Scarica il documento per vederlo tutto.
Scarica il documento per vederlo tutto.
Scarica il documento per vederlo tutto.
Scarica il documento per vederlo tutto.
Scarica il documento per vederlo tutto.
Scarica il documento per vederlo tutto.
vuoi
o PayPal
tutte le volte che vuoi
Introduzione
Secondo la leggenda Didone, rifugiata presso il Re Iarba nel Nord Africa, ottenne la promessa che avrebbe avuto per sé tanta terra quanta avrebbe potuto abbracciarne una pelle di Toro. Didone non si perse d'animo, ma tagliò la pelle in strisce sottilissime che unì poi per formare una corda. Utilizzo poi la corda per delimitare una circonferenza all'interno della quale sarebbe successivamente nata la città di Cartagine. Questo problema di ottimizzazione si chiama isoperimetrico e consiste nel cercare la forma che consente di massimizzare un'area con il vincolo di non superare un perimetro dato. È evidente che nel caso di Didone la forma che massimizza l'area è il cerchio e la circonferenza rappresenta il vincolo sul perimetro. Volendo trasportare il problema in tre dimensioni, si deve ricercare, a parità di superficie data, quella forma che contiene il massimo volume: questa forma è la sfera.
Nel 1615 Keplero aveva scritto Nova Stereometria doliorum vinarorium nel quale affrontava il problema di ottimizzare la forma delle botti di vino. Si doveva da un lato massimizzare il volume contenuto nella botte (e per questo la sfera era l'ideale) e dall'altro ottenere un contenitore comodo, stabile e facilmente impilabile come il parallelepipedo. Keplero pensò ad un compromesso tra Sfera e Parallelepipedo: cosi venne fuori la forma delle botti che ancora oggi utilizziamo.
La possibilità di individuare facilmente i massimi e minimi di una funzione fu resa possibile dall'analisi di Leibniz e Newton e in particolare dal concetto di derivata (tangente della curva): se la -tangente è orizzontale (derivata nulla) siamo in presenza di un punto di stazionarietà, cioè un -massimo, un minimo o un flesso. Per distinguere tra questi tre casi è necessario esaminare la derivata seconda oppure, più banalmente, esaminare il valore della curva immediatamente a sinistra e a destra del punto di stazionarietà.
L'estensione a tre o più dimensioni è un po' più complesso. Invece di risolvere una equazione (derivata nulla) si deve risolvere un sistema di equazioni (derivate parziali nulle), invece di esaminare la derivata seconda si deve esaminare la matrice Hessiana delle derivate parziali seconde.
Lagrange introdusse i suoi "moltiplicatori" nel 1778 come strumento per determinare la configurazione stabile di un sistema meccanico. Successivamente, nel testo del 1797 Theorie de fonctions analytiques, generalizzò il metodo (senza più riferimenti a questioni specifiche di meccanica) a problemi di ottimizzazione, quando tra le variabili esistano una o più equazioni di vincolo e quando non si voglia ricorrere alla eliminazione preliminare di variabili utilizzando le equazioni vincolanti.
Nel 1896 l'ingegnere, economista e sociologo Vilfredo Pareto introdusse il concetto di ottimo che porta il suo nome. Per i problemi di ottimizzazione multicriteri, questo concetto si traduce nella individuazione della frontiera di Pareto cioè dell'insieme delle soluzioni non dominate. Una soluzione si dice non dominata se non esiste alcuna soluzione migliore od uguale ad essa su tutti i criteri e, su almeno un criterio, strettamente migliore.
L'ingegnere statunitense Henry Gantt collaborò con Taylor nell'ambito dello Scientifc Management per migliorare e ottimizzare i tempi e i metodi delle operazioni nelle officine. Nel 1917, lavorando all'ufficio approvvigionamenti dell'esercito durante la 1° guerra mondiale, inventò i suoi celebri diagrammi a barre ancora oggi molto utilizzati nell'ambito della gestione dei progetti.
Nel 1947 Dantzig presentò la sua tesi alla università di Berkeley che verteva sulla esistenza dei moltiplicatori di Lagrange (ovvero variabili duali) per un generico problema di programmazione lineare (PL) che, con variabili continue, positive, soggette a vincoli lineari di maggiore, minore od uguale, consentiva di minimizzare/massimizzare una funzione lineare. L'algoritmo utilizzato denominato Simplesso (Poliedro Convesso) funzionò egregiamente. La prima applicazione di successo fu la determinazione di una dieta a costo minimo, ma vincolata ad avere tutti i nutrienti necessari.
Anche se fu seminale per la programmazione non lineare (PNL) la tesi di dottorato di Karush discussa a Chicago nel 1939, tutti riconoscono nell'articolo del 1951 di Khun e Tucker Non linear Programming la nascita ufficiale della Programmazione non lineare. Le condizioni di Khun-Tucker, per l'ottimo di un problema di PNL, sono necessarie ma non sufficienti, esse rappresentano una generalizzazione dei moltiplicatori di Lagrange perché includono anche i vincoli di disuguaglianza. Sfortunatamente non danno alcuna indicazione pratica per trovare l'ottimo di un problema non lineare.
Già nel 1847 Cauchy aveva sviluppato il metodo del gradiente (steepest ascent/descent: direzione di più ripida salita/discesa) basato sull'uso delle derivate per trovare numericamente il massimo/minimo di una funzione non vincolata. Alla fine degli anni 60 dello scorso secolo Jean Abadie, che lavorava alla Electricitè de France, propose il metodo Gradiente Ridotto e Generalizzato (GRG): potevano essere inclusi vincoli di uguaglianza e disuguaglianza, ma il metodo richiedeva la possibilità di calcolo numerico delle derivate ed inoltre, per problemi non convessi, poteva arrestarsi su di un ottimo locale.
Nel 1960 Land e Doig proposero la tecnica del Branch and Bound per risolvere problemi a numeri interi. Il metodo poteva essere utilizzato da solo o assieme al Simplesso per risolvere problemi di programmazione lineare intera (PLI) o programmazione lineare mista (PLM), in cui alcune variabili sono intere ed altre continue. Successivamente il metodo fu esteso ai problemi di programmazione non lineare intera (PNLI). Il metodo si basa sulla scomposizione del problema in sotto problemi dando valori predefiniti ad alcune variabili (ad esempio 0-1). Si deve pensare ad una struttura ad albero rovesciato in cui vengono esplorati i rami più promettenti (Branch) e chiusi quelli meno interessanti (Bound). Un aspetto interessante del metodo è che ad ogni iterazione è sempre disponibile una soluzione corrente (la migliore trovata sino a quel momento) ed un Upper Bound e un Lower Bound entro cui si troverà la soluzione ottima. Se ad esempio la convergenza all'ottimo è problematica e la differenza percentuale tra UB e LB è inferiore al 2% o 3%, ci si può arrestare accontentandosi della soluzione corrente.
La nascita ufficiale degli algoritmi genetici è considerata il 1975, quando John Holland pubblicò il libro Adaptation in Natural and Artificial Systems. Gli algoritmi genetici nascono da una proficua contaminazione tra biologia e matematica ed in particolare tra le teorie di Mendel e Darwin da una parte e l'ottimizzazione matematica dall'altra. Ecco in sintesi come funzionano:
- Si generano casualmente (come con il metodo Montecarlo) alcune soluzioni,
- Si scelgono le migliori o più adatte (si parla di funzione di fitness),
- Si incrociano i valori delle variabili delle soluzioni migliori (crossover) per generarne di nuove,
- Si creano ulteriori soluzioni mediante mutazioni casuali a partire da quelle precedentemente ottenute,
- Si torna al punto 2 sino ad una ragionevole convergenza.
Intorno agli anni 80 dello scorso secolo si è andata consolidando una nuova disciplina denominata Constraint Programming che interseca vari settori disciplinari quali: Analisi Combinatoria, Matematica Discreta, Ricerca Operativa, Linguaggi di Programmazione, Intelligenza Artificiale. Uno dei risultati concreti della disciplina è stata l'opzione All Different Constraint che consente nei problemi di Ottimizzazione di imporre, ad un set di variabili, di assumere valori tutti diversi.
Il lettore avrà notato che, l'esplosione delle tecniche di ottimizzazione matematica procede nel secondo dopo guerra del 1900 parallelamente alla diffusione dei computer, ancora oggi basati sulla architettura sequenziale ideata da Von Neumann. Forse, se arriveremo ad avere i computer quantistici, anche i metodi e gli algoritmi di ottimizzazione matematica saranno rivoluzionati.
RIFERIMENTI
- Storia della Ottimizzazione
- Ha solo cinquanta anni la programmazione non lineare
- Problemi, Algoritmi e Codici (Smith e Hume)
Funzioni e Derivate (Tempi e Costi di un officina)
Problemi di questo tipo si incontrano in ogni campo di attività quando il fenomeno da studiare possa esprimersi sotto forma di funzione e, dall'andamento di questa, si possano trarre elementi per motivare o addirittura ottimizzare le proprie scelte/decisioni.
In economia e ingegneria gestionale, il lotto economico è un modello di gestione delle scorte che definisce la quantità ottima di acquisto in modo da minimizzare la somma dei costi di approvvigionamento, e dei costi di mantenimento a magazzino (https://it.wikipedia.org/wiki/Lotto_economico).
Il modello di ordinazione a lotti crea delle scorte di ciclo, che vengono idealmente smaltite entro l'ordine successivo. Tuttavia si noti che ordinare a lotti non è l'unica possibilità di gestione delle scorte: infatti, la tecnica del Just in time, nata nell'industria giapponese, prevede che gli ordini vengano 'tirati' direttamente dalla domanda finale (e per questo si dice che il JIT è un sistema pull) e non spinti (push) da una decisione presa a priori, come avviene invece nella gestione a fabbisogno: ciò permette, quando tale tecnica è applicabile, di ridurre significativamente il livello di scorte (fermo restando che esistono varie logiche di misurazione e controllo di tali scorte).
All'inizio degli anni 80 dello scorso secolo una officina attrezzata per la lavorazione di materie pl\astiche è riuscita ad assicurarsi 4 consistenti ordini per le forniture ad un mobilificio della Brianza che opera su scala internazionale.
L'officina è organizzata in modo di poter produrre serie di un solo mobile per volta e pertanto lavora "per magazzino"; quando però debba cambiare lavorazione non ha perdite di produzione perché riesce ad affrontare la risistemazione della linea, la sostituzione degli stampi, e l'attrezzaggio delle macchine ricorrendo a lavoro straordinario notturno o festivo, affrontando, ovviamente un certo costo ogni volta che ciò si verifica.
Gli ordini prevedono tutti la durata di alcuni anni, impegnativa sia per il committente che per il fornitore, e consegne settimanali la cui entità, per ciascun tipo di mobile è sensibilmente inferiore alla capacità media dell'officina nello stesso periodo di tempo. Nel proprio magazzino, l'officina dispone di una superficie libera di 300 mq soltanto, ma avrebbe la possibilità di affittare, nelle immediate adiacenze, un capannone utilizzabile come magazzino, della superficie utile di 400 mq, al canone annuo di 2 milioni di Lit.
Per ciascun tipo di mobile (a, b, c, d) sono noti i seguenti dati, riepilogati in Tabella 1: capacità Produttiva (P), quantità da consegnare per Settimana (S), costo di Allestimento per inizio produzione (A), costo di immagazzinamento (B), costo da prelievo da magazzino (C), costo finanziario dell'immobilizzo di capitale (D) corrispondente ad ogni unità immagazzinata.
Si debba ricercare:
- se la capacità produttiva media dell'officina è sufficiente a consentire il rispetto delle scadenze di consegna,
- il dimensionamento più economico delle serie da produrre per ciascun tipo di mobile.
| Tipo di Mobile | a | b | c | d |
|---|---|---|---|---|
| (P) Prod. Media/settimana n° | 150 | 120 | 180 | 120 |
| (S) Consegne/settimana n° | 30 | 30 | 40 | 20 |
| Costi (*): | ||||
| (A) Avviamento (K.Lit.) | 650 | 570 | 450 | 680 |
| (B) Magazzino/unità (Lit.) | 50 | 50 | 40 | 80 |
| (C) Prelievo da mag./unità (Lit.) | 40 | 40 | 40 | 60 |
| (D) Immobilizzo mag. (Lit./unit*sett) | 25 | 40 | 20 | 50 |
| (*) Un Eur vale circa 375 Lire della fine degli anni 70 |
Ricerca n° 1
(Possibilità di rispettare le scadenze di consegna)
A ciascuno dei mobili da produrre, l'officina dovrà dedicare una quota della sua attività pari al rapporto S/P. Nel caso in esame si avrà quindi:
30/150 + 30/120 + 40/180 + 20/120 = 83.89%
L'officina è pertanto ampiamente in grado di soddisfare gli impegni assunti; è anzi necessaria la ricerca di altre commesse per saturarne l'attività che risulta scoperta di circa: 16.11%
Ricerca n° 2 (prima parte)
(Dimensionamento economico delle serie dei mobili da produrre)
La ricerca consiste nella determinazione del minimo di una funzione. Per determinare quale sia la funzione da minimizzare è però necessario svolgere alcune considerazioni.
Supponiamo che per uno dei tipi di mobile, si prosegua la produzione per un certo numero T1 di settimane. Durante tale periodo, si provvede alla consegna e si immagazzinano le eccedenze; queste ultime al termine di T1, avranno raggiunto la consistenza T1/(P-S). Durante un successivo periodo T2 non si ha produzione di quel tipo di mobile e si effettuano le consegne prelevando da magazzino; è chiaro che questo secondo periodo dovrà avere termine quando T2 = T1*(P-S) /S, perché a tale momento, tutta la giacenza di magazzino sarà stata consegnata.
Chiamando X = T1 + T2 il tempo totale del ciclo, possiamo esprimere T1 in funzione di X, ricavando dalla X -T1 = T1*(P-S)/S che T1 = X*S/P. Nel corso del ciclo di durata X, le unità a magazzino di quel tipo mobile passeranno dal valore zero al valore massimo X*S*(P-S)/P e si ridimensioneranno poi al valore zero; la giacenza media di magazzino sarà pertanto:
X*S*(P-S)/2P
Nel corso del ciclo, di durata X, relativo ad uno dei mobili da produrre, le spese da sostenersi (continuando ad utilizzare i simboli della Tabella 1) saranno:
A + S*X*(B+C)*(P-S)/P + X^2*(P-S)*S*D/2P
Quello che però interessa è trovare il valore di X per il quale sia minima la spesa settimanale; la funzione da minimizzare sarà dunque:
f(X) = A/X + S*(B+C)*(P-S)/P + X*(P-S)*S*D/2P
la cui derivata risulta:
f'(X) = -A/X^2 + (P-S)*S*D/2P
Che si annulla per:
X = RADQ [2*A*P/((P-S)*S*D)]
Si osservi che la funzione f(X) è composta dalla somma di un costo che diminuisce con X, un costo fisso ed un costo che aumenta con X dunque essa presenterà un minimo. Per esserne certi calcoliamo la derivata seconda:
f''(X) = 2*A/X^3
Poiché essa risulta sempre positiva , il valore di X per il quale la derivata prima si azzera, indica il valore minimo dei costi. Dal valore di X si può poi risalire al valore a quello di T1 = X*S/P ed a quello della serie economica da produrre T1*P = X*S.
Tabuliamo, ad esempio, la funzione di costo fa(X), per i mobili di tipo a:
| Settimane: (X) | Costi Decr. | Costi Fissi | Costi Cresc, | Costi Totali |
|---|---|---|---|---|
| 25 | 26000 | 2160 | 7500 | 35660 |
| 30 | 21667 | 2160 | 9000 | 32827 |
| 35 | 18571 | 2160 | 10500 | 31231 |
| 40 | 16250 | 2160 | 12000 | 30410 |
| 45 | 14444 | 2160 | 13500 | 30104 |
| 50 | 13000 | 2160 | 15000 | 30160 |
| 55 | 11818 | 2160 | 16500 | 30478 |
| 60 | 10833 | 2160 | 18000 | 30993 |
| 65 | 10000 | 2160 | 19500 | 31660 |
| 70 | 9286 | 2160 | 21000 | 32446 |
| 75 | 8667 | 2160 | 22500 | 33327 |
| 80 | 8125 | 2160 | 24000 | 34285 |
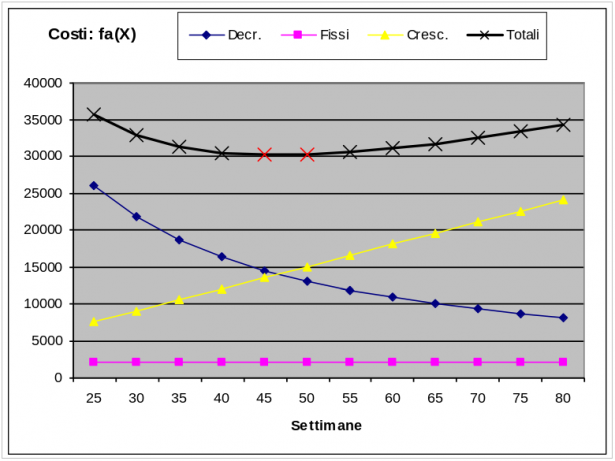
Ricavando dalle formule riportate sopra, separatamente per ciascun mobile, il valore di X otteniamo:
| Tipo di mobile: | a | b | c | d | Media |
|---|---|---|---|---|---|
| Tempi (settimane): | |||||
| Di ciclo (X) | 46.55 | 35.59 | 38.03 | 40.40 | 40.14 |
| Di produzione (T1 = X*S/P) | 9.31 | 8.90 | 8.45 | 6.73 | |
| Prelievo e Consegna (T2 = T1*(P-S)/S) | 37.24 | 26.69 | 29.58 | 33.67 | |
| T1 + T2 = X (Riprova) | 46.55 | 35.59 | 38.03 | 40.40 |
Ricerca n° 2 (seconda parte)
Questi tempi sono incompatibili fra loro e non è possibile combinarli in un programma che consenta di rispettare le date di consegna. Potremo, in prima approssimazione, assumere come tempo di ciclo la media (40.14 settimane) dei tempi di ciclo delle quattro tipologie di mobili, ma per essere più precisi attribuiamo alla X il significato di ciclo per tutte e quattro le serie di mobili. Determineremo poi i tempi di produzione per ogni singolo mobile dalla espressione T1 = X*S/P.
Attribuendo questo significato alla X, la funzione da minimizzare sarà:
F(X) = fa(X) + fb((X) + fc(X) + fd(X)
Utilizzando l'espressione già trovata per la funzione f(X) e ricordando che la derivata di una funzione somma di funzioni è uguale alla somma delle derivate delle singole funzioni si avrà:
F'(X) = -650,000/X^2+300 - 570,000/X^2+450 - 450,000/X^2+311 - 680,000/X^2 +417 =
= -2,350,000/X^2 + 1,478 che si annulla quando è X = RADQ(2,350,000/1,478) = 39.87.
La derivata seconda di F(X) sarà dunque:
dF'(X)/dx = F''(X) = 2*2,350,000/X^3 che risulta sempre positiva.
| arrotond. | |||
| Tempo di ciclo per a+b+c+d X = | 39.87 | settimane | 40 |
| I tempi T1 di produzione risulteranno: | |||
| mobili di tipo a: 39.87*30/150 = | 7.97 | settimane | 8 |
| mobili di tipo b: 39.87*30/120 = | 9.97 | settimane | 10 |
| mobili di tipo c: 39.87*40/180 = | 8.86 | settimane | 9 |
| mobili di tipo d: 39.87*20/120 = | 6.65 | settimane | 7 |
Tabuliamo le funzioni:
| Costi | |||
|---|---|---|---|
| Settimane (X): | F'(X) | F(X) | F''(X) |
| 25 | -2282 | 139952 | 301 |
| 30 | -1133 | 131674 | 174 |
| 35 | -440 | 127872 | 110 |
| 39.87 | 0 | 126868 | 74 |
| 45 | 318 | 127729 | 52 |
| 50 | 538 | 129896 | 38 |
| 55 | 701 | 133012 | 28 |
| 60 | 825 | 136841 | 22 |
| 65 | 922 | 141217 | 17 |
| 70 | 998 | 146023 | 14 |
| 75 | 1060 | 151174 | 11 |
| 80 | 1111 | 156604 | 9 |
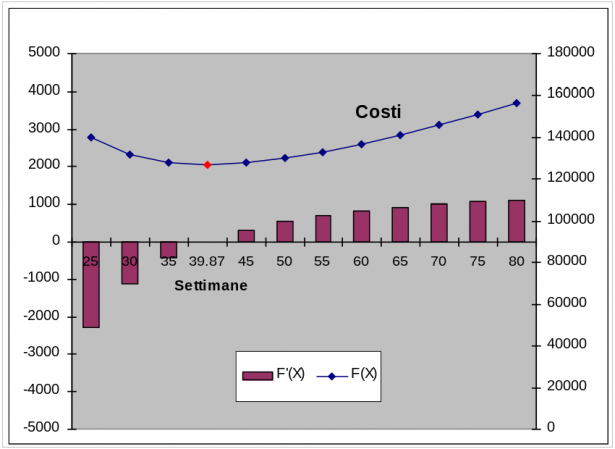
Osserviamo innanzi tutto che assumendo come tempo di ciclo totale la media dei tempi di ciclo per i 4 tipi di mobile (40.14 settimane) avremo commesso solo un piccolo errore rispetto al più corretto tempo di ciclo calcolato in base alla derivata della somma delle quattro funzioni (39.87 settimane). Osserviamo poi, esaminando il grafico, che queste funzioni, f(x) (e quindi anche la loro somma F(X)), hanno un minimo piuttosto piatto. Ciò significa che anche spostandosi un poco a sinistra o a destra del punto di ottimo i Costi totali aumentano di poco. Più per motivi di semplicità organizzativa dell'officina che per facilitare i conteggi, assumiamo dunque un ciclo X dell'officina di 40 settimane e tempi di produzione T1 di: 8, 10, 9, 7 settimane rispettivamente per i mobili di tipo a, b, c, d.
Possiamo dunque concludere la ricerca N° 2 indicando questo programma di lavoro per l'officina:
Mobili di tipo a:
8 settimane di lavorazione con produzione di complessive 8*150 = 1,200 unità, di cui 1,200 - 8*30 = 960 da immagazzinarsi. Alla fine del ciclo, dopo 40 - 8 = 32 settimane dal termine produzione, il magazzino risulterà completamente esaurito; sarebbe quindi opportuna la ricerca di un modesto (ordine del 2% - 3%) incremento della produzione, eventualmente con il ricorso a qualche straordinario, per favorire la formazione di una piccola scorta che assicuri la possibilità di rispettare le scadenze di consegna anche in presenza di un calo temporaneo di produzione, per motivi imprevisti (scioperi, rotture, ecc.) o prevedibili (festività infrasettimanali, chiusura per ferie, ecc.).
Mobili di tipo b:
10 settimane di lavorazione con produzione di complessive 10*120 = 1,200 unità di cui 1,200 - 10*30 = 900 da immagazzinarsi. Alla fine del ciclo dopo 40 -10 = 30 settimane dal termine produzione, il magazzino risulterà completamente esaurito e valgono pertanto le considerazioni del caso precedente.
Mobili di tipo c:
9 settimane di lavorazione con produzione di complessive 9*180 = 1,620 unità, di cui 1,620 - 9*40 = 1260 da immagazzinarsi. Alla fine del ciclo, dopo 40 - 9 = 31 settimane dal termine produzione, il magazzino presenterà un residuo
di 20 unità, insufficiente per essere considerato quale scorta di sicurezza; valgono quindi, anche se in misura inferiore, le considerazioni dei casi precedenti
Mobili di tipo d:
7 settimane di lavorazione con produzione di complessive 7*120 = 840 unità, di cui 840 - 7*20 = 700 da immagazzinarsi. Alla fine del ciclo, dopo 40 - 7 = 33 settimane dal termine produzione, il magazzino quindi un residuo di 40 unità, sufficiente come scorta di sicurezza se si ritiene che questa possa essere limitata all'occorrenza per due settimane di consegne. Adottando questo programma, con il ripetersi dei cicli, il residuo tenderebbe però a divenire costoso ed ingombrante; si dovranno quindi studiare dei provvedimenti (ad esempio, eseguire uno o entrambi gli attrezzaggi di inizio e fine lavorazione in orario normale invece che straordinario) per contrastarne l'aumento.
Ottimizzare la qualità della vita
Un gruppo di ricercatori di una estesa regione ha studiato per anni la salute della popolazione. L'obiettivo era quello di individuare le circostanze ambientali e i comportamenti individuali che potevano ridurre l'insorgere di una specifica malattia. Una analisi statistica preliminare ha consentito di individuare quattro variabili, indipendenti e fondamentali, per comprendere l'insorgere della malattia:
X1: dimensione delle città in cui si vive. Con X1 = 0 rappresentante una città con meno di 10,000 abitanti e X1 = 100 rappresentante qualunque città con più di un milione di abitanti.
X2: livello della attività sportiva della popolazione in una scala compresa tra 0 è 100
X3: tipo di dieta, che può contenere da 10 a 40 unità giornaliere di un particolare tipo di vitamina.
X4: consumo di alcolici misurato tra: 0 (nessun consumo) e 100 (consumo moderato).
Dunque i vincoli sono:
0 <= X1, X2, X4 <= 100
10 <= X3 <= 40
Xi = intero (i = 1,2,3,4)
L'analisi di regressione sui dati rilevati ha portato a definire una curva di risposta che rappresenta, rispetto a una media del 100% di prendere la malattia, la capacità di ridurre il rischio operando sulle quattro variabili elencate. Nella funzione obiettivo Y(Xi) da massimizzare riportata sotto ogni punto percentuale è posto uguale a 1000
Obj. Func: Max! Y(Xi) = 925 - 0.5*x1*x4 + x2^2 -10*x2 + x3^2 - 56*x3 + x4^2 - 20*x4
Il metodo Montecarlo nasce durante la seconda guerra mondiale con le ricerche di Fermi ed Ulam per studiare la diffusione dei neutroni. Esso si è sviluppato ed è cresciuto con l'utilizzo dei computer, della loro velocità di calcolo e capacità di memoria. Si chiama Montecarlo perché è basato sulla capacità dei computer di generare numeri a caso e valutare funzioni. Tra le prime applicazioni in matematica vi è il calcolo di un integrale di una funzione comunque non lineare. Pensate al primo quadrante cartesiano e ad una qualunque funzione tracciabile all'interno di un quadrato che assumiamo di area unitaria. Il computer genererà numeri a caso inferiori (I) e superiori (S) alla curva tracciata. Una stima numerica abbastanza bene approssimata dell'integrale sarà data dal rapporto I/(I+S).
Per trovare una soluzione al nostro problema il metodo Montecarlo genera, ad ogni iterazione, valori casuali interi compresi tra 0 e 100 per le variabili X1, X2, X4 e valori casuali interi compresi tra 10 e 40 per la variabile X3. Per ogni quadrupla di valori Xi generati, il metodo valuta la funzione obiettivo Y(Xi). Il valore di Y(Xi) viene confrontato con una variabile V inizializzata a 0. Se Y > V si pone V = Y e S1 = X1, S2 = X2, S3 = X3, S4 = X4. Se Y < V, si procede a generare una nuova quadrupla di valori Xi. sino a quando non si raggiunge il numero di iterazioni desiderato. Al termine delle iterazioni troveremo memorizzato in V il più grande valore di Y trovato e, all'interno delle Si, i valori di Xi che hanno generato questo valore.
Dopo 5000 iterazioni con Montecarlo si è trovata questa strategia di comportamento (vedi in Bibliografia "Metodo Montecarlo e Ottimizzazione", R. Chiappi):
Y = 16902
X1 = 1 (vivere in una piccola città).
X2 = 99 (fare molto esercizio fisico).
X3 = 28 (unità giornaliere di vitamina da assumere).
X4 = 100 (consumare alcol, ma in modo moderato).
La strategia consente, posta uguale a 100 la media nazionale di contrarre questa malattia, di ridurre del 16.902% la eventualità di contrarla.
Montecarlo, applicato ai problemi di ottimizzazione, fornisce, in generale risultati Sub-ottimali vediamo quindi come, alternativamente alla simulazione, si comportano due algoritmi di programmazione matematica disponibili con il risolutore Excel (GRG, Generalized Reduced Gradient e EVO, Algoritmi Genetici).
Innanzi tutto si osservi che il problema di Programmazione matematica non è dei più semplici in quanto presenta una funzione obiettivo non lineare ed inoltre richiede che le variabili siano intere; pertanto è esclusa la possibilità di utilizzare il metodo del Simplesso. Soluzione trovata con GRG + Branch and Bound:
Y = 17285
X1 = 0 (vivere in una piccola città).
X2 = 100 (fare molto esercizio fisico).
X3 = 40 (unità giornaliere di vitamina da assumere).
X4 = 100 (consumare alcol, ma in modo moderato).
Soluzione trovata con EVO (Algoritmi Genetici):
Y = 17465
X1 = 0 (vivere in una piccola città).
X2 = 100 (fare molto esercizio fisico).
X3 = 10 (unità giornaliere di vitamina da assumere).
X4 = 100 (consumare alcol, ma in modo moderato).
Si osservi che la soluzione migliore è trovata da EVO e la peggiore, come prevedibile, dal metodo Montecarlo ma la differenza, in termini di funzione obiettivo, tra le tre soluzioni è largamente inferiore allo 1%.
Inoltre i valori delle variabili Xi sono quasi uguali, fatta eccezione per il consumo giornaliero di vitamine che è sostanzialmente diverso.
EVO: X3 = 10 (unità giornaliere di vitamina da assumere).
M.C.: X3 = 28 (unità giornaliere di vitamina da assumere).
GRG: X3 = 40 (unità giornaliere di vitamina da assumere).
RIFERIMENTI
Metodo Montecarlo e Ottimizzazione (R. Chiappi)
Il Problema dello zaino
L'articolo prende il titolo Zaino in quanto fa parte di una serie di problemi che possono essere ricondotti, in senso lato, al riempimento di una zaino con diversi carichi con il vincolo di non superare il peso massimo compatibile con lo zaino.
Un'officina meccanica effettua lavori di precisione per i clienti. Ogni macchina produce un tipo particolare di produzione. Verso fine anno il proprietario, avendo ricevuto numerose ordinazioni da parte dei clienti, deve decidere quanti ne può servire e come stabilire la programmazione (scheduling) di una particolare macchina per l'anno successivo. In dettaglio sono arrivati N'ordini da eseguire su tale macchina. La produzione avverrà per campagne, una campagna per ordine. Per ogni ordine è fissata dal cliente la data limite di consegna. L'imprenditore è in grado di fissare per ogni ordine la durata
Deve ora scrivere il piano di produzione cercando di ottimizzare il guadagno totale G, eventualmente tralasciando (i.e. cancellando) qualche ordine se non è compatibile con il piano ottimale. Supponiamo di considerare che la macchina debba produrre N=10 prodotti secondo gli ordini pervenuti dai clienti come sotto riportato
| prodotto | durata (giorni) | scadenza | guadagno |
|---|---|---|---|
| 1 | 22 | 12-ago | 120 |
| 2 | 12 | 25-gen | 80 |
| 3 | 28 | 28-feb | 130 |
| 4 | 50 | 08-nov | 240 |
| 5 | 22 | 30-mar | 170 |
| 6 | 52 | 16-apr | 210 |
| 7 | 51 | 16-giu | 280 |
| 8 | 40 | 08-set | 115 |
| 9 | 23 | 12-nov | 90 |
| 10 | 60 | 14-apr | 200 |
| SOMME | 360 | 1635 |
La prima colonna identifica i prodotti, la terza le scadenze di consegna richieste. La seconda e la quarta, rispettivamente sono una valutazione, da parte dell'imprenditore, delle durate delle campagne e del guadagno (migliaia di €) ottenibile.
La costruzione dello scheduling richiede di trovare l'ordine di lavorazione dei diversi prodotti in modo da effettuare le consegne entro le scadenze richieste. Questo si realizza usando il RISOLUTORE di EXCEL, assumendo come variabili indipendenti i prodotti, che sono numeri interi da 1 a 10. Per far questo si impone per tutte le variabili il vincolo ALL-DIFFERENT. Questo vuol dire che il RISOLUTORE assume come variabili di ottimizzazione i numeri da 1 a 10 (tutti diversi tra loro) ed effettua i calcoli di ottimizzazione permutando l'ordine delle variabili. Inoltre è necessario imporre al RISOLUTORE di assumere come algoritmo di ottimizzazione il metodo EVO (= evolutivo).
Si imposta facilmente il calcolo delle durate a partire dalla tabella precedente e si ottiene la seguente soluzione ottimale
| variabili | data teorica termine produzione | indice rispetto scadenza | data effettiva termine produzione | guadagno |
|---|---|---|---|---|
| 3 | 28-gen | 1 | 28-gen | 130 |
| 5 | 19-feb | 1 | 19-feb | 170 |
| 6 | 12-apr | 1 | 12-apr | 210 |
| 7 | 02-giu | 1 | 02-giu | 280 |
| 1 | 24-giu | 1 | 24-giu | 120 |
| 8 | 03-ago | 1 | 03-ago | 115 |
| 9 | 26-ago | 1 | 26-ago | 90 |
| 10 | 25-ott | 0 | 26-ago | 0 |
| 2 | 07-set | 0 | 26-ago | 0 |
| 4 | 15-ott | 1 | 15-ott | 240 |
| SOMME | 1355 |
Notiamo che la soluzione (colonna a sfondo verde) non riesce a effettuare tutte le produzioni richieste e ne trascura alcune (2 e 10, quelle contraddistinte dall' indice 0). In tal modo il guadagno totale ottenibile, pari a 1355 K€ equivale all'83% del teorico di tabella Dati. I calcoli sono riportati nel file ZAINO-EXCELFILE associato all'articolo, dove si vede che esiste anche una seconda soluzione a pari guadagno.
Ora consideriamo il problema più ampio, con N=25 prodotti
| prodotto | durata (giorni) | scadenza | guadagno |
| 1 | 22 | 12-ago | 120 |
| 2 | 12 | 25-gen | 80 |
| 3 | 28 | 28-feb | 130 |
| 4 | 17 | 08-nov | 240 |
| 5 | 22 | 30-mar | 110 |
| 6 | 13 | 16-apr | 115 |
| 7 | 9 | 16-giu | 130 |
| 8 | 16 | 08-set | 115 |
| 9 | 23 | 12-nov | 90 |
| 10 | 32 | 14-apr | 200 |
| 11 | 12 | 17-set | 80 |
| 12 | 5 | 06-giu | 25 |
| 13 | 11 | 03-mar | 13 |
| 14 | 20 | 31-gen | 40 |
| 15 | 15 | 30-apr | 65 |
| 16 | 14 | 30-ott | 60 |
| 17 | 5 | 04-mar | 15 |
| 18 | 19 | 15-ago | 35 |
| 19 | 10 | 06-set | 15 |
| 20 | 9 | 02-giu | 25 |
| 21 | 18 | 03-apr | 18 |
| 22 | 14 | 30-nov | 15 |
| 23 | 6 | 03-mar | 20 |
| 24 | 8 | 05-dic | 22 |
| 25 | 3 | 08-ott | 15 |
| SOMME | 363 | 1793 |
Se ripetiamo i calcoli, con lo stesso modello, troviamo la seguente soluzione
| variabili | data teorica termine produzione | indice rispetto scadenza (nota) | data effettiva termine produzione | guadagno |
|---|---|---|---|---|
| 3 | 28-gen | 1 | 28-gen | 130 |
| 5 | 19-feb | 1 | 19-feb | 110 |
| 2 | 03-mar | 0 | 19-feb | 0 |
| 23 | 25-feb | 1 | 25-feb | 20 |
| 6 | 10-mar | 1 | 10-mar | 115 |
| 13 | 21-mar | 0 | 10-mar | 0 |
| 10 | 11-apr | 1 | 11-apr | 200 |
| 15 | 26-apr | 1 | 26-apr | 65 |
| 24 | 04-mag | 1 | 04-mag | 22 |
| 20 | 13-mag | 1 | 13-mag | 25 |
| 8 | 29--mag | 1 | 29-mag | 115 |
| 12 | 03-giu | 1 | 03-giu | 25 |
| 17 | 08-giu | 0 | 03-giu | 0 |
| 7 | 12-giu | 1 | 12-giu | 130 |
| 1 | 04-lug | 1 | 04-lug | 120 |
| 16 | 18-lug | 1 | 18-lug | 60 |
| 18 | 06-ago | 1 | 06-ago | 35 |
| 19 | 16-ago | 1 | 16-ago | 15 |
| 11 | 28-ago | 1 | 28-ago | 80 |
| 14 | 17-set | 0 | 28-ago | 0 |
| 25 | 31-ago | 1 | 31-ago | 15 |
| 4 | 17-set | 1 | 17-set | 240 |
| 9 | 10-ott | 1 | 10-ott | 90 |
| 22 | 24-ott | 1 | 24-ott | 15 |
| 21 | 11-nov | 0 | 24-ott | 0 |
| SOMME | 1627 |
Dove sono stati respinti 5 ordini e il guadagno è pari al 91% del massimo potenziale.
In conclusione il RISOLUTORE ha reso molto facile risolvere un problema che, affrontato a mano, sarebbe stato molto lungo e complesso. Nel file ZAINO-EXCELFILE allegato all'articolo sono riportate anche altre soluzioni a pari guadagno totale.
RIFERIMENTI
http://wwwusers.di.uniroma1.it/~asd2/EserciziProg_din.pdf
Un Caso di Ricerca Farmacologica
PRINCIPIO ATTIVO
Una società farmaceutica dopo numerosi anni di lavoro ha sviluppato un nuovo farmaco. Come sappiamo il farmaco è costituito, in generale, da un principio attivo, vale a dire un composto chimico che produce l'effetto terapeutico, e da eccipienti (sostanze aggiuntive). La sperimentazione clinica, in diverse fasi, ha dato esito positivo ed e stata è inviata richiesta all'ente incaricato per autorizzare la messa in commercio del farmaco. Finora sono state prodotte quantità limitate di principio attivo alla scala di laboratorio e pilota. Si deve ora passare alla produzione a scala industriale. Dove è fondamentale soddisfare esigenze finora non considerate: sicurezza, uso di apparecchiature disponibili, …, costo di produzione. A tal fine i tecnici hanno individuato diversi processi alternativi. Ognuno di questi richiede diverse reazioni chimiche (step) per produrre una serie successiva di intermedi fino al prodotto finale, il principio attivo P. Un esempio per chiarire le idee:
La specie chimica iniziale
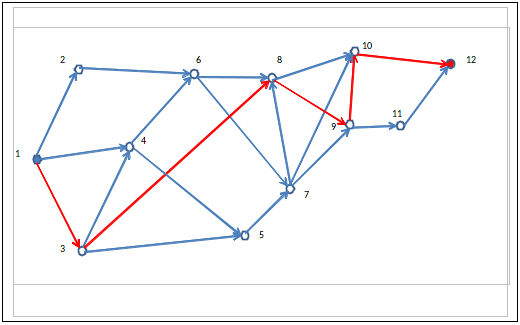
Il disegno sotto riporta i possibili step per passare dal reagente iniziale
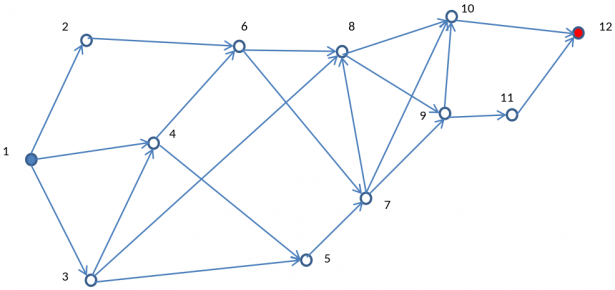
Ognuno dei diversi processi alternativi è individuato da una linea spezzata continua e orientata che parte dal nodo 1 e termina al nodo 12.
Tuttavia numerosi step dei vari processi non sono stati ancora sperimentati ed occorre verificare le loro fattibilità pratica. Si decide quindi di creare un gruppo di chimici esperti (panel) ai quali chiedere un parere di fattibilità per ogni step. In pratica dal panel si ottiene una probabilità media (ovviamente soggettiva, alla De Finetti) di insuccesso per ogni step. Per insuccesso di uno step s'intende che la reazione di tale step non produce resa è selettività adeguate ad un processo industriale: in tal caso lo step è da scartare.
Ogni tratto (linea orientata che unisce due nodi successivi) individua uno step di reazione ed è associato a due costanti:
- costo dello step per kg di principio attivo finale
- probabilità d'insuccesso industriale dello step
Scelto un qualunque percorso (i.e. processo) si ottiene facilmente il costo totale come somma dei costi dei singoli step. Ecco la tabella che riporta costo e probabilità di insuccesso di ogni step di reazione
| nodic cong. | variabili | Costo (€/kg P) | P insuccesso |
|---|---|---|---|
| N1N2 | X12 | 120 | 20% |
| N1N3 | X13 | 60 | 10% |
| N1N4 | X14 | 180 | 30% |
| N2N6 | X26 | 255 | 10% |
| N4N6 | X46 | 165 | 20% |
| N3N4 | X34 | 105 | 3% |
| N3N5 | X35 | 300 | 40% |
| N3N8 | X38 | 600 | 20% |
| N4N5 | X45 | 165 | 30% |
| N5N7 | X57 | 60 | 50% |
| N6N7 | X67 | 210 | 10% |
| N6N8 | X68 | 255 | 20% |
| N7N8 | X78 | 165 | 10% |
| N7N9 | X79 | 210 | 15% |
| N7N10 | X710 | 330 | 20% |
| N8N9 | X89 | 45 | 5% |
| N8N10 | X810 | 120 | 40% |
| N9N10 | X910 | 90 | 2% |
| N9N11 | X911 | 180 | 30% |
| N11N12 | X1112 | 30 | 10% |
| N10N12 | X1012 | 210 | 5% |
Per far in modo di creare una qualunque spezzata continua si può immaginare di associare a ogni step una variabile
Per fare in modo che il processo considerato sia una spezzata continua, si scrive per ogni suo nodo un bilancio materiale tra entrata ed uscita, rappresentato dalle seguenti dodici equazioni:
| Numero eq. | Equazione |
|---|---|
| 1 | -X12-X13-X14+1=0 |
| 2 | X12-X26=0 |
| 3 | X13-X34-X38-X35=0 |
| 4 | X14+X34-X45-X46=0 |
| 5 | X35+X45-X57=0 |
| 6 | X26+X46-X67-X68=0 |
| 7 | X57+X67-X78-X79-X710=0 |
| 8 | X68+X38+X78-X89-X810=0 |
| 9 | X79+X89-X910-X911=0 |
| 10 | X710+X810+X910-X1012=0 |
| 11 | X911-X1112=0 |
| 12 | X1012+X1112-1=0 |
Tali equazioni rappresentano altrettanti vincoli per il problema.
Esistono due possibili funzioni obiettivo (F):
- Costo totale del processo, da rendere minimo
- Probabilità di successo del processo, da rendere massima
Nel primo caso
dove
Nel secondo caso la funzione obiettivo è la probabilità di successo del processo prescelto. Sappiamo che per ogni step la probabilità di successo è il complemento ad 1 della probabilità di insuccesso:
Nella formula compare il termine
Sappiamo inoltre che la probabilità totale di successo del processo è una probabilità composta e, come ci insegna la statistica, è data dal prodotto delle probabilità di successo dei singoli 21 step:
Questa funzione moltiplica tra di loro un certo numero variabili
La ricerca del processo ottimale è quindi di tipo diverso nei due casi. E si esegue per mezzo del Risolutore di EXCEL.
Nel caso di ricerca del costo minimo del processo si può usare con grande facilità il Metodo del Simplesso, ma anche il Metodo GRG Non lineare oppure il Metodo Evolutivo.
Con i dati (tabella sopra riportata) del nostro problema si ottiene con i tre metodi la stessa soluzione:
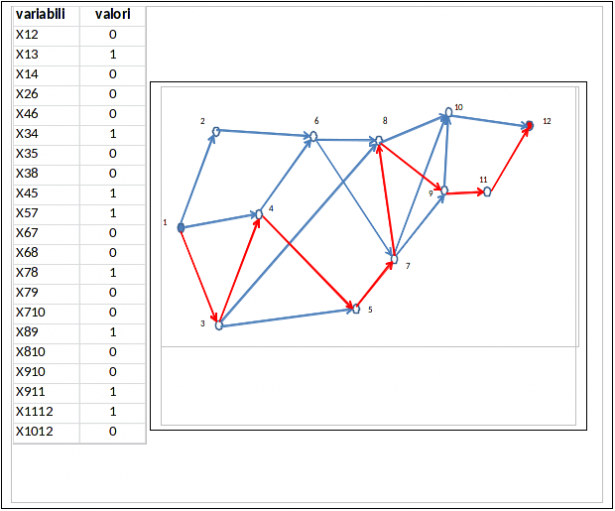
Dove sono evidenziati in rosso gli step che costituiscono il processo ottimale. Il costo totale (minimo) vale 810 €/kg principio attivo.
Nel caso di ricerca della Probabilità Massima di Successo non è possibile impiegare il Simplesso e si deve ripiegare sugli altri due metodi prima descritti. Con GRG ed EVO si ottiene il medesimo processo ottimale, con probabilità pari a 64%.
Avendo trovato risultati diversi con le due diverse funzioni obiettivo, ci troviamo a decidere quale scegliere. Tuttavia potremmo sospendere la decisione e immaginare un nuovo criterio di valutazione che combini i due finora considerati. Dal momento che il costo va minimizzato, mentre la probabilità di successo va massimizzata i due indici non possono essere moltiplicati. Un
accorgimento potrebbe essere quello di considerare come funzione obiettivo un indice multiplo (IM) costituito dal rapporto tra la probabilità ed il costo. Tale indice deve essere massimizzato.
Rifacendo i calcoli con tale IM (IM =6,3) si ritrova come soluzione ottimale la stessa già ottenuta per la ricerca della probabilità massima.
A questo punto abbiamo trovato in definitiva due soluzioni, quelle riportate dai grafi in rosso dei due disegni sopra riportati. Quale scegliamo?
Notiamo che il processo a probabilità massima ha un costo di 1005 €/kg, del 25% superiore a quello a costo minimo.
Notiamo anche che un calcolo di verifica ci permette di determinare quali sono i valori di probabilità e IM per la soluzione a costo minimo: la probabilità è pari al 16%. Ora lanciarsi a sviluppare un processo che ha il 16% di probabilità di successo, è un grande azzardo. La probabilità minima per qualunque decisione sensata è il 50%.
Concludiamo che il processo a probabilità massima è quello da scegliere.
La tabella sotto riporta il confronto tra i processi ottimali per i diversi casi.
| COSTO MIN | PROB. SUCCESSO MAX | INDICE MULT MAX | |
|---|---|---|---|
| SIM, GRG, EVO | GRG, EVO | GRG, EVO | |
| X13 | X13 | X13 | |
| X34 | X38 | X68 | |
| X45 | X89 | X89 | |
| X57 | X910 | X910 | |
| X78 | X1012 | X1012 | |
| X89 | |||
| X911 | |||
| X1112 | |||
| COSTO | 810 | 1005 | 1005 |
| PROB. | 16% | 64% | 64% |
È anche possibile ricercare manualmente un certo numero di soluzioni e riportare in un diagramma (sotto riportato) l'inverso del costo vs la probabilità di successo
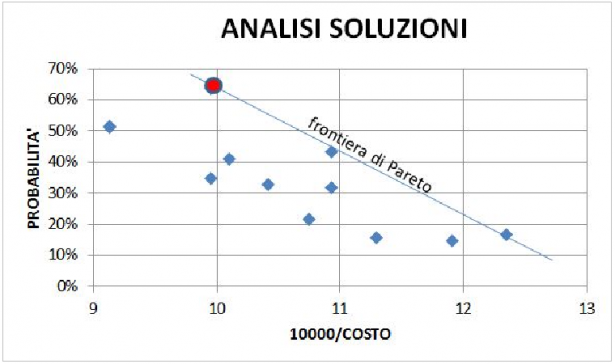
nel quale si individua la frontiera dei valori ottimali per le due variabili. Questa linea è definita frontiera di Pareto. Tutti i punti (soluzioni possibili) compresi tra gli assi coordinati e la frontiera non sono ottimali. Nel diagramma appaiono tre punti di frontiera, tutti ottimali, ma il preferito è quello cerchiato in rosso che genera l'unica probabilità accettabile.
Tutti i calcoli relativi a questo capitolo sono riportati nel file PRINCIPIOATTIVO-EXCELFILE associato all'articolo.
RIFERIMENTI
Farmaco (Hume)
Il Problema del Commesso Viaggiatore

Un commesso viaggiatore deve presentare la sua merce nelle n città che rientrano nelle sue competenze. Poiché le città sono piuttosto distanti l'una dall'altra e il costo degli alberghi e ristoranti è piuttosto salato, programma il suo giro in modo da passare e pernottare una e una sola volta in ciascuna città e, alla fine del giro, tornare velocemente in sede per comunicare gli ordini acquisiti e programmare i prossimi viaggi. Il nostro commesso è un appassionato di teoria dei grafi, sa quindi che un problema tipico è quello di cercare i cammini hamiltoniani (il nome deriva dal matematico, fisico, \astronomo irlandese W.R. Hamilton) nei grafi connessi (nessun nodo è isolato). In un grafo si chiama cammino hamiltoniano un circuito chiuso che tocca una e una sola volta tutti i nodi del grafo, tornando al termine al nodo di partenza. Solitamente in un grafo i cammini hamiltoniani sono molto numerosi, ma al nostro viaggiatore interessa cercare quello a costo (carburante, pedaggi autostradali, ecc.) minore. Per programmare il suo viaggio il commesso si è procurato una cartina geografica comprendente la cittadina sul mare in cui vive e le altre 11 città da visitare. Poi ha disegnato il grafo riportato sotto in cui i nodi (rettangoli) rappresentano le 12 città e gli archi le vie di comunicazione esistenti tra esse. Sugli archi sono poi riportati i costi totali di trasferimento.
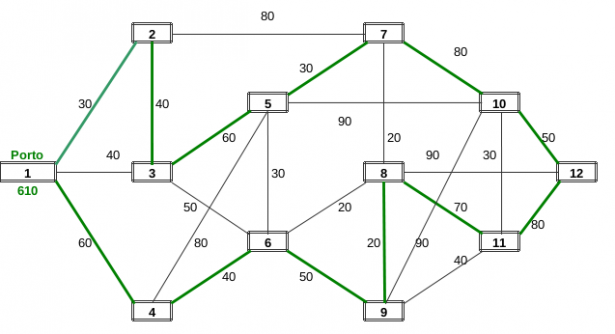
Approccio del circuito ingordo
Quale è il cammino Hamiltoniano di costo minimo? Non disponendo dell'ultima versione del risolutore di Excel, che con gli algoritmi genetici (Devo) permette di affrontare problemi non lisci (in pratica quelli in cui non si possono usare le derivate) e con l'opzione Alldifferent permette di affrontare problemi combinatori, il commesso viaggiatore decide di affidarsi ad una euristica di tipo Greedy (Ingorda) e per prima cosa traccia, con un compasso, un cerchio al centro del grafo. Decide poi confrontando i costi (30, 40, 60) delle tre vie uscenti dalla sua città di fare un giro in senso orario dirigendosi per prima cosa verso la città 2. Successivamente procede scegliendo sempre le vie più economiche verso le città vicine, ma correggendo la scelta in considerazione del fatto che, non gli conviene creare vicoli cechi, deve comunque toccare tutte le città e non gli conviene tornare su città già visitate. Il circuito trovato, per tentativi ed errori, è segnato in verde sul grafo e il conteggio dei costi totali e riportato nella tabella sottostante.
| 1 > 2 | 30 |
| 2 > 3 | 40 |
| 3 > 5 | 60 |
| 5 > 7 | 30 |
| 7 > 10 | 80 |
| 10 > 12 | 50 |
| 12 > 11 | 80 |
| 11 > 8 | 70 |
| 8 > 9 | 20 |
| 9 > 6 | 50 |
| 6 > 4 | 40 |
| 4 > 1 | 60 |
| Totale Costo | 610 |
Approccio della programmazione matematica
Questo tipo di problemi è molto importante per le compagnie aeree, per le aziende che distribuiscono prodotti petroliferi, per quelle che progettano schede dei circuiti integrati, per le analisi dei dati, per lo studio delle sequenze del DNA, ecc.
Nel caso di problemi schematizzabili come quello del Commesso Viaggiatore occorre trovare il cammino Hamiltoniano che ottimizza la funzione obiettivo.
Ritorniamo a considerare il problema appena visto sopra, che era stato approcciato con il metodo Greedy. Come è stato detto con il Greedy si trova una soluzione valida, ma non è sicuro che sia quella ottimale. Il metodo sicuro per trovare il cammino a costo minimo è la verifica di tutte le possibili alternative, che in questo caso sono dell'ordine di grandezza di 12! = 479 milioni, una ricerca chiaramente impossibile.
Un sistema pratico molto efficace/efficiente è il RISOLUTORE di EXCEL con il criterio di ricerca EVOLUTIVO, accoppiato al sistema di vincolo ALL-DIFFERENT. Se lo applichiamo al problema in esame basta costruire una matrice che riporta il costo tra le varie coppie di città (i valori del grafo visto in precedenza). Poi, con un semplice uso della funzione EXCEL CERCA.VERT() si dà modo al RISOLUTORE di determinare i costi di ogni tratta. Il RISOLUTORE, molto potente, genera una sequenza di percorsi alternativi che con il metodo evolutivo raggiungono facilmente la soluzione ottima. Qui sotto sono riportate la tabella dei costi e il risultato finale de RISOLUTORE (raggiunto in 40 secondi di elaborazione). Il risultato di costo minimo (540 è alquanto inferiore a quello trovato dal Greedy, 610). Notiamo che è stato attribuito un costo grandissimo (9999) a tutte le coppie di città prive di collegamento. È questo un trucco (una penalizzazione) per evitare di scrivere un gran numero di vincoli.
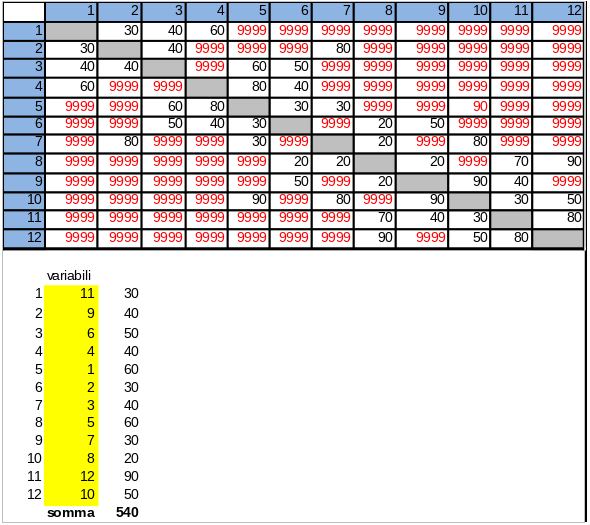
I calcoli relativi ai due problemi del commesso viaggiatore sopra descritti sono riportati nel file CIRCUITOMINIMO-EXCELFILE.
Per esplorare le potenzialità del RISOLUTORE nel caso di problemi TSA (travelling salesman) di maggiori dimensioni, si è provato a immaginare un commesso che debba visitare 50 città, nell' ipotesi immaginaria che tutte siano collegate tra di loro. Si costruita pertanto una matrice simmetrica 50 x 50 riportata sotto). I valori in tabella sono le distanze tra le coppie di città. Si desidera trovare il viaggio che le visiti tutte una sola volta rendendo minimo il percorso totale.

Visualizza immagine più grande
Anche in questo caso il RISOLUTORE funzione molto bene, tuttavia, partendo da situazioni iniziali diverse, trova sette diverse soluzioni, in cui la funzione obiettivo varia meno del 2%, che possono quindi essere considerate praticamente equivalenti (intorno a 4000 km). Quella ottima è di 3980 km. Il tempo di convergenza del RISOLUTORE è di circa 140 s.
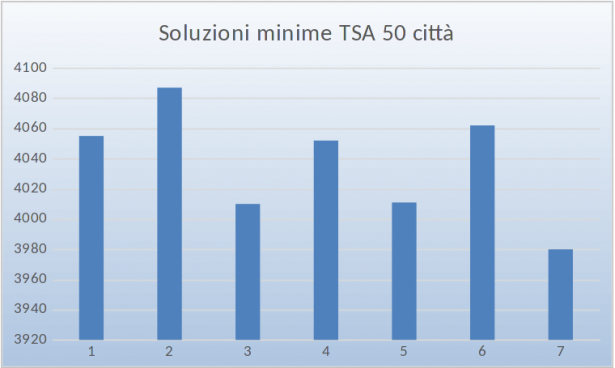
Per vedere la matrice ed i risultati dell'ottimizzazione conviene consultare il file TSA50EXCELFILE associato all'articolo.
RIFERIMENTI
- Gritzmann, Brandenberg, "Alla ricerca della via più breve, un'avventura matematica", Springer Verlag 2005
- Grafi e Reti (R. Chiappi)
- Risolvere il problema del Commesso Viaggiatore in Excel usando Devo e Alldifferent Constraint(Julian Vasilev)
Problemi di Sequenze nella produzione
Possiamo pensare le aziende di produzione posizionate in uno spazio cartesiano in cui sulle ascisse sono rappresentati i volumi di produzione (da basso ad alto) e sulle ordinate il livello di personalizzazione dei prodotti (da basso ad alto). Partendo dal basso a destra abbiamo le Raffinerie che hanno una produzione continua ed in alto a sinistra le aziende che operano per progetti come quelle che progettano/costruiscono aerei, raffinerie, condotte, piattaforme marine ecc.
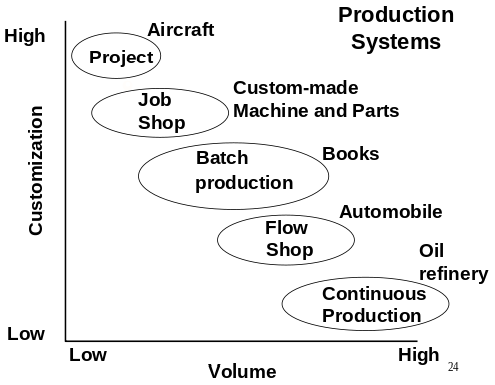
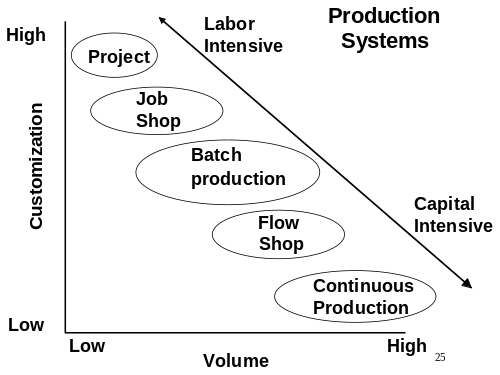
Nel grafico riportato sotto si mostra come le aziende che hanno una produzione continua sono ad alta intensità di capitale (tecnologia, robotica, ecc.), mentre quelle che operano per progetti sono ad alta intensità di lavoro (umano). Va comunque detto che oggi, anche molte aziende che operano per progetti si sono spostate verso il Capital Intensive. Valga per tutti l'esempio delle aziende che progettano/costruiscono condotte per il trasporto di petrolio e gas. Se le condotte sono costruite a terra (On-Shore) i progetti sono effettivamente Labour Intensive, ma se le condotte sono costruite a mare (Off-Shore) i progetti sono fortemente Capital Intensive.
Nel seguito, ci concentreremo su sistemi di produzione intermedi denominati rispettivamente Flow Shop (più semplici) e Job Shop (più complessi). I sistemi Flow Shop, che sono sostanzialmente quelli della classica catena di montaggio, possono essere schematizzati dal problema di lavorare n pezzi diversi, che hanno tempi di lavorazione diversi sulle macchine, ma tutti con la stessa sequenza ordinata delle macchine o dei reparti. Il problema consiste nel trovare quale tra le n! sequenze possibili consente di terminare tutte lavorazioni nel tempo minimo possibile.
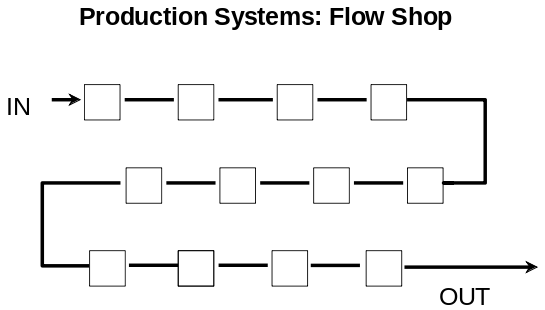 The above picture is a conceptual view of a flow shop. The boxes represent machines and the arrows show the job flow. Every job visits the machines in the same order.
The above picture is a conceptual view of a flow shop. The boxes represent machines and the arrows show the job flow. Every job visits the machines in the same order.Per iniziare supponiamo che le macchine siano solo due (A, B), in quanto in questo caso esiste l'algoritmo di Johnson che offre, semplicemente, la possibilità di trovare la sequenza ottimale.
Ecco l'algoritmo:
- Si scelga il più breve tempo di lavorazione tra le due macchine e i pezzi non lavorati.
- Se i tempi più brevi sono più di uno se ne scelga uno a caso.
- Se il tempo appartiene alla macchina A, la lavorazione del pezzo si pone al primo posto.
- Se il tempo appartiene alla macchina B, la lavorazione del pezzo si pone all'ultimo posto.
- Si cancelli il pezzo da ulteriori considerazioni
- Se gli n pezzi sono stati tutti lavorati si salti al punto 7 altrimenti si torni al punto 1
- Fine
Vediamo un esempio numerico (in questo esempio le sequenze possibili sono: 5! = 120)Tempi di lavorazione:
| Pezzo | Mach. A | Mach. B | Totale |
|---|---|---|---|
| 1 | 5 | 2 | 7 |
| 2 | 1 | 6 | 7 |
| 3 | 9 | 7 | 16 |
| 4 | 3 | 8 | 11 |
| 5 | 10 | 4 | 14 |
| Totali | 28 | 27 | 55 |
Si sceglie come primo il pezzo 2 che ha durata minima (1) sulla macchina A.
Si sceglie come ultimo il pezzo 1 che ha durata minima (2) sulla macchina B.
Si sceglie come secondo il pezzo 4 che ha durata 3 sulla macchina A.
Si sceglie come penultimo il pezzo 5 che ha durata 4 sulla macchina B.
Dunque la sequenza ottimale è: 2,4,3,5,1.
| Macchina A | Macchina B | |||
|---|---|---|---|---|
| Sequenza | Inizio | Fine | Inizio | Fine |
| 2 | 0 | 1 | 1 | 7 |
| 4 | 1 | 4 | 7 | 15 |
| 3 | 4 | 13 | 15 | 22 |
| 5 | 13 | 23 | 23 | 27 |
| 1 | 23 | 28 | 28 | 30 |
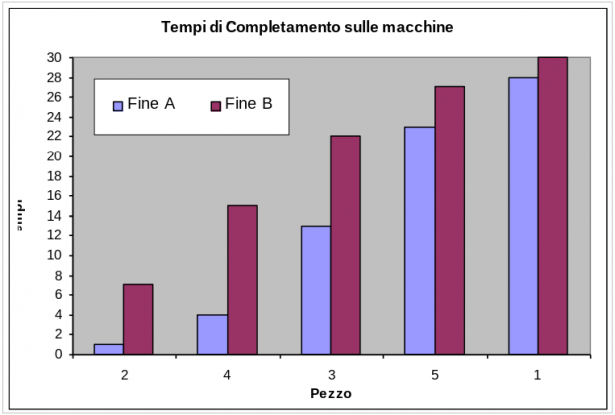
In conclusione il tempo totale minimo è di 30 ore. I tempi morti sono di 3 ore per la macchina B e di 2 ore per la macchina A.
Officina di carpenterie metalliche
Un' officina di carpenteria metallica deve produrre 4 lotti di pezzi diversi attraverso 7 lavorazioni da eseguirsi nell'ordine in cui vengono elencate: taglio, piegatura, foratura, saldatura, sgrassaggio, fosfatizzazione, verniciatura. I lotti non sono suddivisibili, cioè non è possibile una lavorazione su un lotto, prima che sul lotto stesso non sia terminata la lavorazione precedente.
È noto il tempo necessario perché ciascuno di essi passi attraverso ogni singola lavorazione; tali tempi espressi in ore di calendario lavorativo sono quelli riepilogati in tabella:
| Lotto | Taglio | Piegat. | Forat. | Saldat. | Sgrass. | Fosfat. | Vernic. | Totali | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 20 | 20 | 40 | 30 | 10 | 15 | 25 | 160 | |
| 2 | 10 | 15 | 30 | 40 | 20 | 20 | 30 | 165 | |
| 3 | 35 | 0 | 10 | 40 | 10 | 20 | 30 | 145 | |
| 4 | 10 | 10 | 0 | 25 | 20 | 25 | 30 | 120 | |
| Totali | 75 | 45 | 80 | 135 | 60 | 80 | 115 | 590 |
I valori 0 stanno ad indicare che il pezzo tre non richiede piegatura e quello 4 non richiede foratura.
In questo esempio abbiamo 7 lavorazioni e non 2 dunque l'algoritmo ottimale di Johnson non può essere applicato. Possiamo però utilizzarlo ugualmente prendendo in considerazione solo la prima (Taglio) e l'ultima lavorazione (Verniciatura). In questa maniera avremo rapidamente una soluzione, probabilmente buona, ma probabilmente sub-ottimale. Ecco la soluzione considerando i tempi minimi di Taglio e Verniciatura:
1° 10 Lotto 2
2° 10 Lotto 4
3° 20 Lotto 1
4° 35 Lotto 3
| Lotto | Taglio | Piegat. | Forat. | Saldat. | Sgrass. | Fosfat. | Vernic. | Attesa |
| 2 | 10 | 25 | 55 | 95 | 115 | 135 | 165 | 0 |
| 4 | 20 | 35 | 55 | 120 | 140 | 165 | 195 | 75 |
| 1 | 40 | 60 | 100 | 150 | 160 | 180 | 220 | 60 |
| 3 | 75 | 75 | 110 | 190 | 200 | 220 | 245 | 100 |
Nella tabella riportata sopra abbiamo indicato nella prima colonna i quattro lotti ordinati secondo la sequenza euristica trovata con l'algoritmo di Johnson applicato alla prima (Taglio) e all'ultima (Verniciatura) operazione.
Le colonne successive riportano il tempo di completamento (fine) di ciascuna operazione. Nell'ultima colonna abbiamo riportato i tempi totali di attesa che ciascun lotto deve subire per attendere il termine delle lavorazioni precedenti.
Il primo lotto ad essere lavorato è il N°2. Per esso i tempi di attesa sono chiaramente nulli, infatti la prima riga della tabella è calcolata semplicemente come il tempo progressivo di termine delle varie lavorazioni. La fine ciclo (Verniciatura) tempo 165 coincide ovviamente con il totale dei tempi di lavorazione (165) del lotto 2.
Il calcolo dei tempi di termine delle operazioni successive non è così semplice in quanto si deve tener conto dei tempi di attesa che si possono generare in quanto può essere ancora in lavorazione il lotto precedente.
Consideriamo, ad esempio il lotto 1 che viene lavorato per terzo:
Per iniziare le operazioni di Taglio è necessario attendere 20, in modo che siano completate le operazioni sul lotto 4. Successivamente le operazioni di Piegatura e Foratura avvengono senza attese. Per iniziare l'operazione di Saldatura è necessario attendere 20. Infatti il tempo di fine sarà calcolato come Max (100,120) + 30 = 150. Procedendo in modo analogo si trova che per l'operazione di Sgrassatura il tempo di attesa è nullo, mentre per le operazioni finali di Fosfatizzazione e Verniciatura i tempi di attesa sono rispettivamente 5 e 15. Riepilogando il Totale delle Attese per il lotto 1 è:
Taglio (20) + Piegatura e Foratura (0) + Saldatura (20) + Sgrassatura (0) + Fosfatizzazione (5) + Verniciatura (15) = 20 + 20 + 5 + 15 = 60.
Infine osserviamo che l'ultimo lotto, il 3°, ha un tempo totale di attesa di 100 che sommato al suo tempo interno di ciclo (145) fornisce il tempo totale di fine di tutte le lavorazioni: 245.
Applichiamo ora l'algoritmo evolutivo:
| fine operaz. | fine operaz. | fine operaz. | fine operaz. | fine operaz. | fine operaz. | fine ciclo | |
| Lotto | Taglio | Piegat. | Forat. | Saldat. | Sgrass. | Fosfat. | Vernic. |
| 4 | 10 | 20 | 20 | 45 | 65 | 90 | 120 |
| 2 | 20 | 35 | 65 | 105 | 125 | 145 | 175 |
| 3 | 55 | 55 | 75 | 145 | 155 | 175 | 205 |
| 1 | 75 | 95 | 135 | 175 | 180 | 200 | 230 |
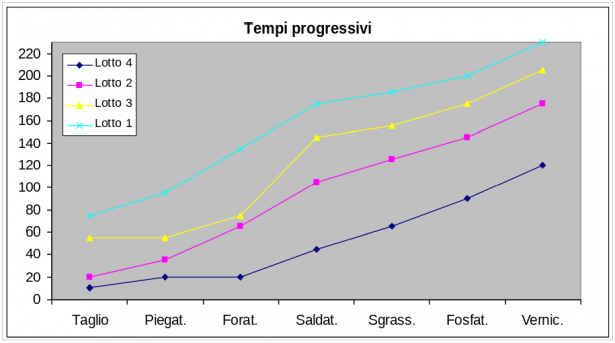
In conclusione con l'algoritmo evolutivo e il vincolo All-different si ottiene un tempo di ciclo di 230, notevolmente migliore, infatti:
(245 - 230)/245 = 15/245 = circa 6%
Il problema del Job Shop è molto più complesso di quello precedentemente presentato del Flow Shop. In questo caso infatti tutti i pezzi/lotti non vengono lavorati sequenzialmente dalle varie macchine/reparti con un ordine uguale per tutti, ma possono transitare dai vari reparti/isole con un ordine diverso. Teoricamente il numero delle soluzioni possibili cresce notevolmente: se nel Flow Shop erano n! (essendo n il numero il numero dei pezzi/lotti da trattare) nel Job Shop diventano
Consideriamo, per esemplificare, un semplice caso in cui abbiamo 3 pezzi (1,2,3) da lavorare su 4 macchine (A, B, C, D) con sequenze diverse.
L'ordine di lavorazione assegnato sia A, B, C, D per il pezzo 1, B, C, D, A per il pezzo 2, ed A, C, B, D per il pezzo 3. I tempi delle singole lavorazioni siano quelli riportati in tabella:
| Macchine | ||||||
| Pezzi | A | B | C | D | Totali | |
| 1 | 3 | 2 | 3 | 5 | 13 | |
| 2 | 2 | 5 | 8 | 6 | 21 | |
| 3 | 4 | 6 | 1 | 3 | 14 | |
| Totali | 9 | 13 | 12 | 14 | 48 |
Per trovare la sequenza migliore in questo caso (3! = 3*2 = 6 sequenze possibili) utilizzeremo, considerando la scarsa numerosità delle soluzioni, un metodo esaustivo, cioè l'esame delle 6 sequenze possibili. Per farlo impiegheremo un diagramma inventato dallo ingegnere statunitense Henry Gantt. Questo diagramma è ancora oggi il principale strumento, assieme alle WBS e alle tecniche reticolari, che utilizzano le aziende operanti per progetto.
Sulla intestazione delle colonne è riportato il tempo progressivo delle lavorazioni, mentre sulle righe sono riportate le 6 sequenze possibili. Il diagramma mostra in maniera chiara la lavorazione dei pezzi sulle macchine, rispettando le precedenze richieste, gli inevitabili tempi di attesa e i tempi di completamento.
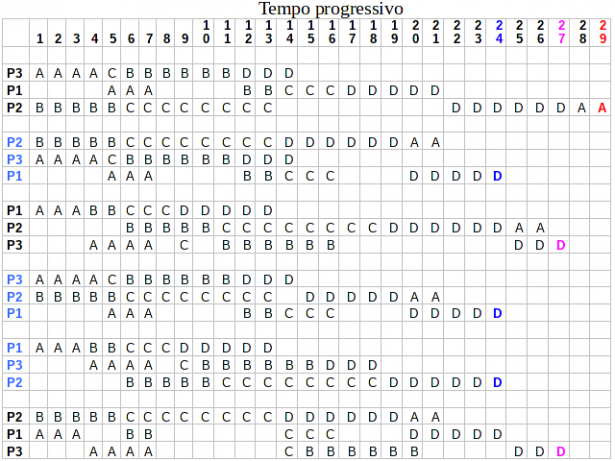
Dalla analisi del diagramma di Gantt appare che il tempo ottimale è di 24 unità di tempo che può essere realizzato con tre sequenze diverse di lavorazione dei pezzi: P2 P3 P1, P3 P2 P1 e P1 P3 P2.
I problemi di sequenza di produzione, trattati in questo capitolo dell'articolo, sono stati analizzati e risolti con il RISOLUTORE di EXCEL con il metodo evolutivo ed il vincolo ALL-DIFFERENT (vedere il file SEQUENZE DI PRODUZIONE-EXCELFILE per un confronto con i risultati riportati sopra, problema per problema).
RIFERIMENTI
- S.M. Johnson, Optimal Two and Three- Stage Production Schedules with Set-up T\times Included, Naval Research Logistics Quarterly, Marzo 1954R
- Chiappi, U. De Simoni, La decisione motivata, lavoro non pubblicato, Ivrea 1979
Mahendra S. Bakshi and Sant Ram Arora, Management Science, INFORMS: http://www.jstor.org/stable/2628801
Fatturato, o biglietti venduti, per il teatro?
La ricerca di ottimo in presenza di due o più obiettivi (Multigoal) riveste notevole importanza in numerosi settori. Esiste un'ampia letteratura in proposito.
Validi autori italiani (vedere i RIFERIMENTI) hanno descritto e sviluppato un problema di questo tipo per la gestione di un importante teatro. L'argomento da essi trattato è molto complesso ed ha richiesto un notevole impegno e tecniche sofisticate. Qui ci limitiamo ridefinire il problema in termini diversi e molto semplificati per mettere in luce la problematica ed un modo per inquadrare/risolvere il problema.
La gestione economica di un teatro è una faccenda piuttosto delicata. Lo scopo di questa istituzione è diffondere la cultura tra le generazioni. Tuttavia l'allestimento di una stagione teatrale è molto impegnativo ed i ricavi ottenibili dalla vendita dei biglietti di solito non coprono i numerosi costi. A questo sopperisce in parte lo Stato (in alcuni casi anche i privati) fornendo dei finanziamenti. Che tuttavia sono di entità limitata e possono diminuire in anni di crisi economica. Veniamo ora al problema.
Il direttore di un teatro sta elaborando il piano per la prossima stagione. Da un lato deve fare il massimo per diffondere la cultura ed a tal fine deve fare in modo di riempire adeguatamente i posti disponibili. Un teatro mezzo vuoto offre una pessima immagine e viene meno alle sue finalità. Dall'altro lato deve ottenere un fatturato adeguato per cercare di chiudere almeno in pareggio la stagione. I due obiettivi sono contr\astanti: biglietti costosi attirano pochi spettatori.
Inoltre gli spettacoli sono diversi tra loro. Alcuni sono più importanti e costosi e giustificano prezzi più elevati per raggiungere il pareggio. Immaginiamo di fare, insieme al direttore, la programmazione di uno spettacolo. Una prassi, di uso comune in questo teatro, consiste nel suddividere i posti in due gruppi o settori. Quelli più vicini al palcoscenico saranno più costosi (per spettatori abbienti e appassionati), gli altri saranno più economici, per attirare il largo pubblico ed in particolare i giovani.
Sulla base di una lunga esperienza il direttore è riuscito a costruire la curva di domanda per i due tipi di settori. Come sappiamo la curva di domanda rappresenta la quantità di biglietti che gli spettatori sarebbero disposti ad acquistare in funzione del prezzo del biglietto. Nel nostro caso specifico le curve di domanda per i due tipi di biglietti sono riportati del seguente diagramma (sono stati ipotizzati i dati, riportati nel file EXCEL associato all'articolo)
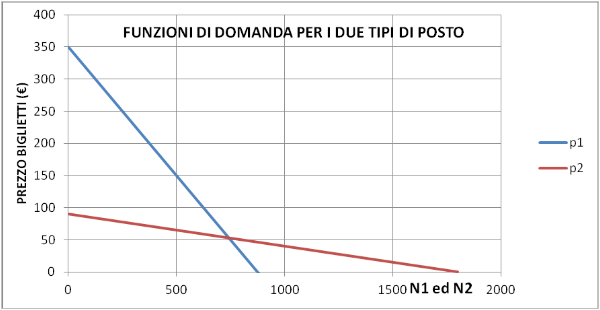
La curva in rosso si riferisce ai biglietti economici, quella in azzurro a quelli costosi. In ascisse è riportato il numero di biglietti venduti per i due tipi di posti. Notiamo che le pendenze delle due rette di domanda sono ben diverse. La curva rossa ha pendenza (coefficiente angolare) piccola. Ciò vuol dire che questo tipo di pubblico (economico) è molto sensibile al prezzo: un piccolo aumento di prezzo fa ridurre molto la domanda. Il contrario avviene per la curva rossa (biglietti costosi): una variazione importante di prezzo fa variare molto meno la domanda. Le persone benestanti (retta azzurra) non si preoccupano molto se il prezzo varia. La teoria economica ci insegna che il prezzo di mercato si ottiene intersecando la curva di domanda con quella di offerta (che viene decisa dal direttore del teatro). Il quale stabilisce il prezzo per i due tipi di posto. Questo vuol dire che la curva di offerta è una retta orizzontale. Qui sotto si vede un esempio.
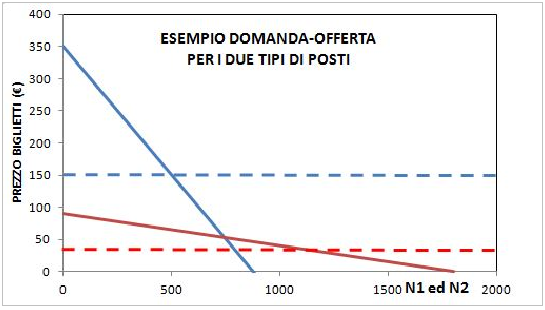
Questo diagramma spiega chiaramente che la decisione per i due prezzi (linee tratteggiate) determina, all'incrocio delle rispettive curve il numero dei biglietti (N1 ed N2) che saranno comprati per i due tipi di posti. In alternativa se il direttore fissa il numero di biglietti da vendere per i due tipi di posti, risultano definiti i prezzi da applicare. Vediamo ora di quantificare il problema.
Curve di domanda:
Ricavi:
Ora definiamo le funzioni obiettivo:
Ricavo:
Numero biglietti venduti:
Che sono entrambe funzioni delle variabili indipendenti
Vincoli:
Dove
È facoltà del direttore decidere quanti posti assegnare al biglietto costoso e quanti al biglietto economico.
Dal momento che abbiamo due funzioni obiettivo risulta evidente che non è possibile ottimizzarle contemporaneamente. Quello che possiamo fare è trovare diverse situazioni di ottimo parziale e confrontarle tra di loro, per valutare quale ci sembra preferibile sulla base di considerazioni addizionali.
Un primo approccio consiste nelle ricerca dell'ottimo di ciascuna funzione obiettivo trascurando l'altra. A questo fine possiamo usare il Risolutore di EXCEL.
Massimizzazione del Ricavo:
| F11 = R1 | 26471 |
| F12 = R2 | 36000 |
| F1 = R1 + R2 | 62471 |
| F2 = N1 + N2 | 776 |
Massimizzazione del numero di biglietti venduti:
| F11 = R1 | 22809 |
| F12 = R2 | 4875 |
| F1 = R1 + R2 | 27684 |
| F2 = N1 + N2 | 1440 |
Un criterio alternativo, molto usato nella PROGRAMMAZIONE MULTIGOAL è l'uso di una media pesata. Si ricerca il massimo della funzione seguente:
Dove
Quindi i due pesi dovrebbero avere diversi ordini di grandezza.Un criterio spesso usato si definisce Utopia-Nadir. In pratica, usando i risultati delle precedenti ottimizzazioni per le singole variabili, si costruisce la seguente matrice
| valori funzioni obiettivo | ||
| Funzioni da max. | R | N |
| R | 62471 | 776 |
| N | 27684 | 1400 |
Si costruisce ora una matrice derivata, dove la prima riga (Utopia) riporta i valori massimi (diagonale principale), la seconda riga (Nadir) i valori minimi (in questo caso i valori rimanenti) della matrice precedente.
| R | N | |
| UTOPIA | 62471 | 1400 |
| NADIR | 27684 | 776 |
Si costruiscono ora i fattori di normalizzazione [math]\theta_i[/math]
dove a denominatore si è riportata la differenza tra Utopia e Nadir per le rispettive funzioni R ed N.
Qui sotto i risultati
| R | N | |
| (\theta) | 2,87E-05 | 1,60E-03 |
Ora possiamo introdurre un parametro t che ci permette di pesare le due funzioni. Si assume peso t per la funzione R e peso 1-t per la funzione N. Assumiamo che sia
A questo punto si può costruire la funzione obiettivo pesata e normalizzata:
Ora ricerchiamo il massimo della FOB in funzione delle variabili indipendenti
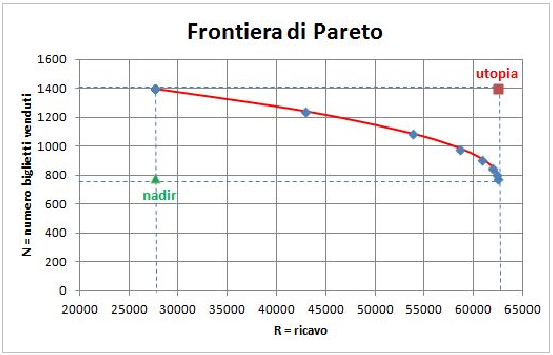
La linea tracciata rappresenta il limite delle condizioni ottime multi goal e, come è noto, si definisce Frontiera di Pareto, dal nome del suo inventore, il celebre scienziato italiano (ingegnere ed economista) Vilfredo Pareto.
In conclusione non siamo riusciti a trovare l'ottimo complessivo, dal momento che non era possibile ottimizzare contemporaneamente le due variabili (R, N), ma abbiamo offerto al decision maker (il presidente del teatro) il limite delle soluzioni ottime. Starà a lui decidere dove posizionarsi sulla frontiera.
Tutti i dati ed i calcoli sono riportati nel fileTEATRO-EXCELFILE associato all'articolo.
APPENDICE AL PROBLEMA DEL TEATRO
La ricerca dell'ottimo (nel nostro caso il massimo) multi goal in definitiva è riconducibile a far variare i valori delle variabili indipendenti (
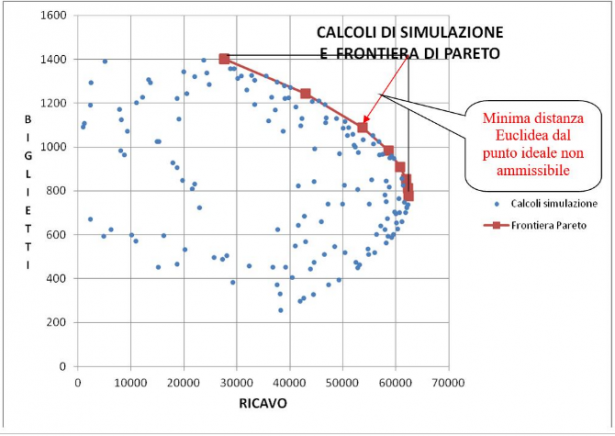
Si è ottenuta una nuvola di punti tutti compresi nella frontiera di Pareto che abbiamo visto prima.
I punti azzurri al disotto della frontiera sono dominati da quelli della frontiera vicina e quindi rappresentano soluzioni non ottimali. Notiamo che la frontiera è quasi simmetrica e che il ramo inferiore della frontiera (non tracciato nel disegno) non ha interesse pratico. La soluzione ottimale deve essere scelta nel ramo superiore, vale a dire sulla linea rossa. Sta al decision maker stabilire se posizionarsi sul lato sinistro della frontiera, in tal modo privilegiando il riempimento dei posti oppure, al contrario, sul lato destro, favorendo gli incassi, oppure ancora, nella sona centrale, cercando un qualche tipo di bilanciamento tra ricavo e biglietti.
RIFERIMENTI
- Goal Programming and Extensions, J. P. Ignizio, Lexitongs Books, Toronto, 1976
- http://virgo.unive.it/wpideas/storage/2016wp20.pdf
- https://books.google.it/books?id=rbLxCAAAQBAJ&lpg=PA216&dq=utopia%20nadir&hl=it&pg=PA216#v=onepage&q&f=false
- http://cims.nyu.edu/~gn387/glp/lec1.pdf
- https://ocw.mit.edu/courses/engineering-systems-division/esd-77-multidisciplinary-system-design-optimization-spring-2010/lecture-notes/MITESD_77S10_lec15.pdf
- http://www.maths-in-industry.org/miis/233/1/fmipw1-6.pdf
- Cinzia De Simoni, Ricerca della soluzione ottimale nei problemi di sequenza, Tesi di laurea, Università degli Studi di Torino 1976
PRINCIPIO ATTIVO: dati costo e probabilità insuccesso per gli step
nodi cong. variabili valori Costo (€/kg P) Pinsuccesso Numero eq. Equazione
N1N2 X12 0 120 20% 1 -X12-X13-X14+1=0 0
N1N3 X13 1 60 10% 2 X12-X26=0 0
N1N4 X14 0 180 30% 3 X13-X34-X38-X35=0 0
N2N6 X26 0 255 10% 4 X14+X34-X45-X46=0 0
N4N6 X46 0 165 20% 5 X35+X45-X57=0 0
N3N4 X34 0 105 3% 6 X26+X46-X67-X68=0 0
N3N5 X35 1 300 40% 7 X57+X67-X78-X79-X710=0 0
N3N8 X38 0 600 20% 8 X68+X38+X78-X89-X810=0 0
N4N5 X45 0 165 30% 9 X79+X89-X910-X911=0 0
N5N7 X57 1 60 50% 10 X710+X810+X910-X1012=0 0
N6N7 X67 0 210 10% 11 X911-X1112=0 0
N6N8 X68 0 255 20% 12 X1012+X1112-1=0 0
N7N8 X78 1 165 10%
N7N9 X79 0 210 15%
N7N10 X710 0 330 20% Nelle colonna valori è stato impostato, per tentativo, un processo iniziale compatibile con i vincoli (12 equazioni ai nodi)
N8N9 X89 1 45 5%
N8N10 X810 0 120 40%
N9N10 X910 0 90 2%
N9N11 X911 1 180 30%
N11N12 X1112 1 30 10%
N10N12 X1012 0 210 5%
PRINCIPIO ATTIVO: risultato processo che minimizza il costo di produzione con Simplesso
variabili valori Costo (€/kg P) EQUAZIONI
X12 0 120 1 -X12-X13-X14+1=0 0
X13 1 60 2 X12-X26=0 0
X14 0 180 3 X13-X34-X38-X35=0 0
X26 0 255 4 X14+X34-X45-X46=0 0
X46 0 165 5 X35+X45-X57=0 0 10
X34 1 105 6 X26+X46-X67-X68=0 0 2 6 8 12
X35 0 300 7 X57+X67-X78-X79-X710=0 0
X38 0 600 8 X68+X38+X78-X89-X810=0 0
X45 1 165 9 X79+X89-X910-X911=0 0
X57 1 60 10 X710+X810+X910-X1012=0 0 11
X67 0 210 11 X911-X1112=0 0 9
X68 0 255 12 X1012+X1112-1=0 0 4
X78 1 165 1
X79 0 210
X710 0 330 COSTO 810 min
X89 1 45 7
X810 0 120
X910 0 90
X911 1 180 5
X1112 1 30 3
X1012 0 210
PRINCIPIO ATTIVO: risultato processo che minimizza il costo di produzione con GRG
variabili valori Costo (€/kg P) EQUAZIONI
X12 0 120 1 -X12-X13-X14+1=0 0
X13 1 60 2 X12-X26=0 0
X14 0 180 3 X13-X34-X38-X35=0 0
X26 0 255 4 X14+X34-X45-X46=0 0
X46 0 165 5 X35+X45-X57=0 0 10
X34 1 105 6 X26+X46-X67-X68=0 0 2 6 8 12
X35 0 300 7 X57+X67-X78-X79-X710=0 0
X38 0 600 8 X68+X38+X78-X89-X810=0 0
X45 1 165 9 X79+X89-X910-X911=0 0
X57 1 60 10 X710+X810+X910-X1012=0 0 11
X67 0 210 11 X911-X1112=0 0 9
X68 0 255 12 X1012+X1112-1=0 0 4
X78 1 165 1
X79 0 210
X710 0 330 COSTO 810 min
X89 1 45 7
X810 0 120
X910 0 90
X911 1 180 5
X1112 1 30 3
X1012 0 210
PRINCIPIO ATTIVO: risultato processo che minimizza il costo di produzione con Evolutivo
variabili valori Costo (€/kg P) EQUAZIONI
X12 0 120 1 -X12-X13-X14+1=0 0
X13 1 60 2 X12-X26=0 0
X14 0 180 3 X13-X34-X38-X35=0 0
X26 0 255 4 X14+X34-X45-X46=0 0
X46 0 165 5 X35+X45-X57=0 0 10
X34 1 105 6 X26+X46-X67-X68=0 0 2 6 8 12
X35 0 300 7 X57+X67-X78-X79-X710=0 0
X38 0 600 8 X68+X38+X78-X89-X810=0 0
X45 1 165 9 X79+X89-X910-X911=0 0
X57 1 60 10 X710+X810+X910-X1012=0 0 11
X67 0 210 11 X911-X1112=0 0 9
X68 0 255 12 X1012+X1112-1=0 0 4
X78 1 165 1
X79 0 210
X710 0 330 COSTO PROBABILE 810 min
X89 1 45 7
X810 0 120 Questo metodo raggiunge il minimo con difficoltà
X910 0 90 dopo diverse ricerche di minimo partendo
X911 1 180 da processi iniziali diversi 5
X1112 1 30 3
X1012 0 210
PRINCIPIO ATTIVO: ricerca del processo a massima probabilità di successo con metodo GRG
variabili valori Pinsuccesso Psuccesso EQUAZIONI
X12 0 20% 100% 1 -X12-X13-X14+1=0 0
X13 1 10% 90% 2 X12-X26=0 0
X14 0 30% 100% 3 X13-X34-X38-X35=0 0
X26 0 10% 100% 4 X14+X34-X45-X46=0 0
X46 0 20% 100% 5 X35+X45-X57=0 0 10
X34 0 3% 100% 6 X26+X46-X67-X68=0 0 2 6 8 12
X35 0 40% 100% 7 X57+X67-X78-X79-X710=0 0
X38 1 20% 80% 8 X68+X38+X78-X89-X810=0 0
X45 0 30% 100% 9 X79+X89-X910-X911=0 0
X57 0 50% 100% 10 X710+X810+X910-X1012=0 0 11
X67 0 10% 100% 11 X911-X1112=0 0 9
X68 0 20% 100% 12 X1012+X1112-1=0 0 4
X78 0 10% 100% 1
X79 0 15% 100% PROBABILITA PROCESSO 64% max
X710 0 20% 100%
X89 1 5% 95% 7
X810 0 40% 100%
X910 1 2% 98%
X911 0 30% 100% 5
X1112 0 10% 100% 3
X1012 1 5% 95% Ricerca probabilità di successo massima con metodo GRG non lineare
PRINCIPIO ATTIVO: ricerca del processo a massima probabilità di successo con metodo Evolutivo
variabili valori Pinsuccesso Psuccesso EQUAZIONI
X12 0 20% 100% 1 -X12-X13-X14+1=0 0
X13 1 10% 90% 2 X12-X26=0 0
X14 0 30% 100% 3 X13-X34-X38-X35=0 0
X26 0 10% 100% 4 X14+X34-X45-X46=0 0
X46 0 20% 100% 5 X35+X45-X57=0 0 10
X34 0 3% 100% 6 X26+X46-X67-X68=0 0 2 6 8 12
X35 0 40% 100% 7 X57+X67-X78-X79-X710=0 0
X38 1 20% 80% 8 X68+X38+X78-X89-X810=0 0
X45 0 30% 100% 9 X79+X89-X910-X911=0 0
X57 0 50% 100% 10 X710+X810+X910-X1012=0 0 11
X67 0 10% 100% 11 X911-X1112=0 0 9
X68 0 20% 100% 12 X1012+X1112-1=0 0 4
X78 0 10% 100% 1
X79 0 15% 100% PROBABILITA' PROCESSO 64% max
X710 0 20% 100%
X89 1 5% 95% 7
X810 0 40% 100%
X910 1 2% 98%
X911 0 30% 100% 5
X1112 0 10% 100% 3
X1012 1 5% 95% Ricerca probabilità di successo massima con metodo GRG non lineare
PRINCIPIO ATTIVO: ricerca del processo a massimo indice multiplo con metodo GRG L'indice multiplO è il rapporto PROBABILITA/COSTO
variabili valori Pfallimento
Psuccesso Costo (€) EQUAZIONI
X12 0 20% 100% 120 1 -X12-X13-X14+1=0 0
X13 1 10% 90% 60 2 X12-X26=0 0
X14 0 30% 100% 180 3 X13-X34-X38-X35=0 0
X26 0 10% 100% 255 4 X14+X34-X45-X46=0 0
X46 0 20% 100% 165 5 X35+X45-X57=0 0 10
X34 0 3% 100% 105 6 X26+X46-X67-X68=0 0 2 6 8 12
X35 0 40% 100% 300 7 X57+X67-X78-X79-X710=0 0
X38 1 20% 80% 600 8 X68+X38+X78-X89-X810=0 0
X45 0 30% 100% 165 9 X79+X89-X910-X911=0 0
X57 0 50% 100% 60 10 X710+X810+X910-X1012=0 0 11
X67 0 10% 100% 210 11 X911-X1112=0 0 9
X68 0 20% 100% 255 12 X1012+X1112-1=0 0 4
X78 0 10% 100% 165 1
X79 0 15% 100% 210 PROBABILITA' PROCESSO 64%
X710 0 20% 100% 330 COSTO PROCESSO 1005 P
€/kg
X89 1 5% 95% 45 IM = FOB = PROB/COSTO 6,3 max 7
X810 0 40% 100% 120
X910 1 2% 98% 90
X911 0 30% 100% 180 5
X1112 0 10% 100% 30 3
X1012 1 5% 95% 210
PRINCIPIO ATTIVO: ricerca del processo a massimo indice multiplo con metodo Evolutivo
variabili valori Pfallimento
Psuccesso Costo (€) EQUAZIONI
X12 0 20% 100% 120 1 -X12-X13-X14+1=0 0
X13 1 10% 90% 60 2 X12-X26=0 0
X14 0 30% 100% 180 3 X13-X34-X38-X35=0 0
X26 0 10% 100% 255 4 X14+X34-X45-X46=0 0
X46 0 20% 100% 165 5 X35+X45-X57=0 0 10
X34 0 3% 100% 105 6 X26+X46-X67-X68=0 0 2 6 8 12
X35 0 40% 100% 300 7 X57+X67-X78-X79-X710=0 0
X38 1 20% 80% 600 8 X68+X38+X78-X89-X810=0 0
X45 0 30% 100% 165 9 X79+X89-X910-X911=0 0
X57 0 50% 100% 60 10 X710+X810+X910-X1012=0 0 11
X67 0 10% 100% 210 11 X911-X1112=0 0 9
X68 0 20% 100% 255 12 X1012+X1112-1=0 0 4
X78 0 10% 100% 165 1
X79 0 15% 100% 210 PROBABILITA' PROCESSO 64%
X710 0 20% 100% 330 COSTO PROCESSO 1005
X89 1 5% 95% 45 IM = FOB = PROB/COSTO 6,3 max 7
X810 0 40% 100% 120
X910 1 2% 98% 90
X911 0 30% 100% 180 5
X1112 0 10% 100% 30 3
X1012 1 5% 95% 210 Ricerca probabilità di successo massima con metodo GRG non lineare
VERIFICA: CALCOLO PROBABILITA' E INDICE MULTIPLO PER LA SOLUZIONE CHE RENDE MINIMO IL COSTO
Pfallimento
Psuccesso Costo (€) EQUAZIONI
variabili valori
X12 0 20% 100% 120 1 -X12-X13-X14+1=0 0
X13 1 10% 90% 60 2 X12-X26=0 0
X14 0 30% 100% 180 3 X13-X34-X38-X35=0 0
X26 0 10% 100% 255 4 X14+X34-X45-X46=0 0
X46 0 20% 100% 165 5 X35+X45-X57=0 0
X34 1 3% 97% 105 6 X26+X46-X67-X68=0 0
X35 0 40% 100% 300 7 X57+X67-X78-X79-X710=0 0
X38 0 20% 100% 600 8 X68+X38+X78-X89-X810=0 0
X45 1 30% 70% 165 9 X79+X89-X910-X911=0 0
X57 1 50% 50% 60 10 X710+X810+X910-X1012=0 0
X67 0 10% 100% 210 11 X911-X1112=0 0
X68 0 20% 100% 255 12 X1012+X1112-1=0 0
X78 1 10% 90% 165
X79 0 15% 100% 210 PROBABILITA' PERCORSO SINTESI 16%
X710 0 20% 100% 330 COSTO 810
X89 1 5% 95% 45 IM = FOB = PROB/COSTO 2,0
X810 0 40% 100% 120
X910 0 2% 100% 90
X911 1 30% 70% 180
X1112 1 10% 90% 30
X1012 0 5% 100% 210
SINTESI RISULTATI COSTO MIN PROB. SUCCESSO MAX INDICE MULT MAX SOLUZIONE PRESCELTA
SIM, GRG, EVO GRG, EVO GRG, EVO X13
X13 X13 X13 X68
X34 X38 X68 X89
X45 X89 X89 X910
X1012
X57 X910 X910
X78 X1012 X1012
X89
X911
X1112
COSTO 810 1005 1005
PROB. 16% 64% 64%
ANALISI DI ALCUNE SOLUZIONI E FRONTIERA OTTIMALE
I/COSTO*10000 PROB
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
#REF! #REF!
PROBLEMI DI SEQUENZE NELLA PRODUZIONE
Autori: Hume& Smith
Tempi di lavorazione:
Lotto Taglio Piegat. Forat. Saldat. Sgrass. Fosfat. Vernic. Totali
20 20 40 30 10 15 25 160
1 10 15 30 40 20 20 30 165
2 35 10 40 10 20 30 145
3 0
10 10 25 20 25 30 120
4 0
75 45 80 135 60 80 115 590 590
Totali Soluzione Ottima:
fine operaz. fine operaz. fine operaz. fine operaz. fine operaz. fine operaz. fine ciclo
Lotto Taglio Piegat. Forat. Saldat. Sgrass. Fosfat. Vernic.
10 20 20 45 65 90 120
4 20 35 65 105 125 145 175
2 55 55 75 145 155 175 205
3 75 95 135 175 185 200
1 230 FOB
NON TROVA ALTRE SOLUZIONI
Macchine:
Pezzi A B C D Totali
1 5 4 6 16
1 7 3 7 2 19
2 4 8 5 7 24
3 2 1 2 7 12
4 14 17 18 22 71 71
Totali Soluzione Ottima:
Macchine: variabili
Pezzi A B C D = PEZZI A B C D
2 3 5 12 2 3 5 12
4 4
3 8 12 18 3 8 12 18
1 1
7 16 21 28 7 16 21 28
3 3
14 19 26 14 19 28
2 30 2 30 FOB
. non trova altre soluzioni
Macchine:
Pezzi A B C D E F Totali
2 0 3 1 2 9
1 1
0 3 0 4 6 5 18
2 1 6 0 6 6 4 23
3 1 2 1 3 0 10
4 3
6 10 5 12 17 10 60 60
Totali fine operaz. fine operaz. fine operaz. fine operaz. fine operaz. fine ciclo
variabili=Pezzi A B C D E F
0 3 3 7 13 18
2 2 3 6 8 15 19
1 3 9 9 15 21 25
3 6 10 12 16 24 25
4 Non trova altre soluzioni .
Macchine:
Pezzi A B C D E F Totali
4 7 3 5 3 24
1 2
7 4 3 8 2 4 28
2 5 4 8 9 1 7 34
3 6 1 7 4 3 23
4 2
3 4 4 7 2 5 25
5 21 25 19 36 12 21 134 134
Totali Soluzione Sub-ottima:
Macchine:
fine operaz. fine operaz. fine operaz. fine operaz. fine operaz. fine ciclo
Pezzi A B C D E F
2 8 9 16 20 23
4 9 13 16 24 26 30
2 12 17 21 31 33 38
5 17 21 29 40 41 48
3 21 28 32 45 48 50
1 FOB .
ALTERNATIVA: che viene trovata raramente
4
5
2
3
1 Tempi di lavorazione:
Pezzo: Mach. A Mach. B
5
1 2
6
2 1
3 9 7
3 8
4 10 4
5 Soluzione Ottima:
Mach. A: Mach. B:
Sequenza: Inizio Fine Inizio Fine
0 1 1 7
2 1 4 7 15
4
3 4 13 15 22
13 23 23 27
5 23 28 28
1 30 Soluzione Ottima:
Mach. A: Mach. B:
variabile
=Pezzo: Inizio Fine Inizio Fine alternativa
0 3 3 11 2
4 3 4 11 17 4
2 4 13 17 24 3
3 13 23 24 28 5
5 23 28 28 1
1 30 FOB
Tempi di lavorazione:
Pezzo: Mach. A Mach. B Mach. C Mach. D dur tot
2 4 5 1 12
1 2 5 3 6 16
2 Soluzione Ottima:
fine operaz. fine operaz. fine operaz. fine ciclo
Pezzo: Mach. A Mach. B Mach. C Mach. D
2 6 11 12
1 4 11 14 20
2 .
Non credo si possa usare il Risolutore.
Comunque si vede che le lavorazioni possono essere iniziate contemporaneamente e non ci sono sovrapposizioni. Il tempo totale è quindi quello del prodotto B che richiede più tempo
MASSIMIZZAZIONE DELLA FUNZIONE MEDIA PESATA
Neff 1400 N° posti
a1 300 ord. or. D posti cari
€/posto
b1 0,85 c.ang. D. posti cari
€/posto^2
a2 120 ord. or. D posti economici
€/posto
b2 0,1 c.ang. D. posti economici
€/posto^2
N1 100 176,5 450
N2 100 600,0 1300
N = N1 + N2 776,5
% RIEMPIMENTO 55%
valori funzioni obiettivo
Funzione da max. R N R N
R 62471 776 UTOPIA 62471 1400
N 27684 1400 NADIR 27684 776
valori W (pesi) t R N UTOPIA NADIR
F11 = R1 26471 CALCOLO PESI 0,00001 27684 1400
F12 = R2 36000 R N 0,1 27684 1400
W 0,00002874688501
1,60E-03
F1 = R1 + R2 62471 2,87E-05 0,2 27684 1400
F2 = N1 + N2 776 1,60E-03 0,3 27684 1400
FOB = F1*t*WR+F2*(1-t)*WN 1,8 t 1-t 0,4 42920 1244
1 0 0,5 53781 1088
0,6 58609 984
Prezzi di soluzione ottima R N 0,7 60875 910
62471 776
p1 150 0,8 61928 854
€/posto
p2 60 0,9 62363 811
€/posto 1,0 62471 776
62471 1400
27684 776
MASSIMIZZAZIONE NUMERO BIGLIETTI VENDUTI ( al limite)
Neff 1400 N° posti
a1 300 ord. or. D posti cari
€/posto
b1 0,85 D. posti cari
€/posto^2c.ang.
a2 120 ord. or. D posti economici
€/posto
b2 0,1 D. posti economici
€/posto^2c.ang.
lim.inf. variabili lim.sup.
N1 100 242,1 450
N2 100 1157,9 1300
N = N1 + N2 1400,0
% RIEMPIMENTO 100% t 0,99999
F11 = R1 22809
F12 = R2 4875
F1 = R1 + R2 27684 R
F2 = N1+N2 1400 N
FOB = (1-t)/R + t*N 1400,262842
Prezzi di soluzione ottima
p1 94,2 €/posto
p2 4,2 €/posto
MASSIMIZZAZIONE DEL RICAVO( al limite)
Neff 1400 N° posti
a1 300 ord. or. D posti cari
€/posto
b1 0,85 D. posti cari
€/posto^2c.ang.
a2 120 ord. or. D posti economici
€/posto
b2 0,1 D. posti economici
€/posto^2c.ang.
lim.inf. variabili lim.sup.
N1 100 176,5 450
N2 100 600,0 1300 55%
N = N1 + N2 776,5
% RIEMPIMENTO 55% t 0,99999
F11 = R1 26471
F12 = R2 36000
F1 = R1 + R2 62471 R
F2 = N1 + N2 776 N
FOB = t*R+(1-t)*N 62471
Prezzi di soluzione ottima
p1 150,0 €/posto
p2 60,0 €/posto
DESCRIZIONE E DATI Ascisse punti di massimo relativo Ricavo

{kind=link}