Question: I want to clarify my understanding of the basics of OLS regression in matrix form.
Let's assume we have 2 different independent variables $x_1$ and $x_2$.
Our 'model' will be the plane that lives in $\mathbb{R^3}$ that minimises the sum of squared distances between each point on the plane corresponding to observations of our pair of independent variable points $x_{1i}$ & $x_{2i}$ and the corresponding point $y_i$. These individual distance are our estimated residuals call them $\bar μ_i$
Vector form: In vector form we instead have single vectors in $n$ dimensional space, whereby our number of observations defines $n$.
$y$ and each $x_i$ variable form $n$ dimensional vectors in this space.
The span of these $x_i$ vectors will form a hyperplane $X$ in this $n$ dimensional space. Now our vector $\hat y$ which represents our model. This is the orthogonal projection of $y$ onto the plane $X$, and the coefficients that define the linear combination of $x_i$ vectors that give $\hat y$ are the weights of our $β_ι$ parameters in our model.
What's bothering me is that in [this lecture series][1] the author states that.
>In OLS regression we are trying to get as close to this dependent variable vector $y$ as we can, given that we don't have a vector or a space $X$ which is as highly dimensional [as $y$].
What's bothering me here is that, each of the vectors $x_i$ are as "highly dimensional" as $y$ because they live in the same $n$ dimensional space, but i appreciate that $X$ does not span all of $\mathbb{R^n}$ and so we can not get y with just a linear combination of our different $x_i$. **Is this interpretation correct?**
Question: If we had the "true model" then this distance between the true plane call it $\bar X$ and $y$ would be our error term vector $u$ and i assume that $u$ would itself be the linear combination or many other unaccounted for independent variables?
Question: When i try and visualise this, naturally all i come up with is a plane in $\mathbb{R^3}$ and then $y$ is outside of this plane. This visual analogy implies that only one $x$ variable is missing i.e. we just need a 3rd linearly independent vector. But surely for any dimension of space we chose. Our $y$ is just one vector away from $X$ as we can always point wise define an extra vector $y - lin(X)$ and indeed if we take $\hat y$ to be our vector $\in X$ then $y - \hat y$ is just $\bar u$ our residual vector.
So i'm unclear how to think about this missing extra dimensionality the author mentions. I suppose in reality this $\bar u$ could be decomposed into many more LI vectors of uncounted for independent variables. But I would appreciate clarification.
[1]: https://youtu.be/oWuhZuLOEFY?t=206
2 messaggi
• Pagina 1 di 1
Intuition Of Linear algebra Econometrics
![]() da CormJack » 19/06/2023, 22:13
da CormJack » 19/06/2023, 22:13
- CormJack
- Starting Member

- Messaggio: 4 di 4
- Iscritto il: 10/06/2023, 17:10
Re: Intuition Of Linear algebra Econometrics
![]() da ghira » 20/06/2023, 07:16
da ghira » 20/06/2023, 07:16
CormJack ha scritto: This visual analogy implies that only one $x$ variable is missing i.e. we just need a 3rd linearly independent vector. But surely for any dimension of space we chose. Our $y$ is just one vector away from $X$ as we can always point wise define an extra vector $y - lin(X)$ and indeed if we take $\hat y$ to be our vector $\in X$ then $y - \hat y$ is just $\bar u$ our residual vector.
But don't you have multiple observations? If you choose an extra vector to get a perfect prediction for one observation it might not work for the others.
-
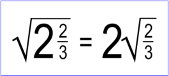
ghira - Cannot live without

- Messaggio: 2421 di 4015
- Iscritto il: 11/09/2019, 09:36
2 messaggi
• Pagina 1 di 1
Torna a Statistica e probabilità
Chi c’è in linea
Visitano il forum: Nessuno e 1 ospite